Kotlin 기본 내용 정리
- 서론
- 1장. 코틀린 소개
- 2장. 코틀린 기초
- 3장. 함수의 정의와 호출
- 4장. 클래스, 객체, 인터페이스
- 5장. 람다로 프로그래밍
- 6장.코틀린 타입 시스템
- 7장. 연산자 오버로딩과 기타 관례
- 8장. 고차 함수: 파라미터와 반환 값으로 람다 사용
- 9장. 제네릭스
- 10장. 애노테이션과 리플렉션
서론
아래 내용은 코틀린 인 액션을 읽고 정리한 내용입니다.
예제에 대한 실습 내용은 깃 저장소를 참고하세요.
1장. 코틀린 소개
- 정적 타입 지정 언어
- 객체지향 & 함수형프로그래밍 지원
- 기존 자바 프레임워크 완벽 지원, 새로운 도구 제공
- 실용적, 안전성(NullPointerException), 간결성, 상호운용성(Java 호환)
2장. 코틀린 기초
함수와 변수
- 함수를 선언할때는 fun 키워드 사용.
- 파라미터 이름 뒤에 그 파라미터의 타입을 사용.
- 함수의 기본 구조
fun max(a: Int, b: Int) : Int { return ... }- 반환 타입이 생략 가능. 컴파일러가 함수 본문 식을 분석해 지정함 → “타입 추론(type interface)”
- 식이 본문인 함수의 반환 타입만 생략가능하다
- 코틀린에서 if는 “식(expression)” 이다. “문(statement)” 이 아니다.
- val : 변경 불가능한 참조변수
- 참조가 가리키는 객체의 내부 값은 변경 가능함.
- var : 변경 가능한 참조변수
- 모든 변수를 val 키워드로 우선 선언 → 나중에 필요하면 var로 변경하는 방식으로 진행
- 문자열 템플릿 →
println(”Hello, $name!”)또는println(”Hello, ${name}!”)사용.
클래스와 프로퍼티
- 코틀린에서 기본 가시성은 public 이다.
- 프로퍼티는 코틀린에서 자바의 필드와 접근자 메서드를 대신한다.
- val : 읽기전용 프로퍼티 → 컴파일 시, private 변수, getter() 생성
- var : 변경가능 프로퍼티 → 컴파일 시, private 변수, getter() & setter() 생성
- setter 메소드 대신
person.isMarried = false와 같이 사용한다.
enum 과 when
- 코틀린에서 enum은 소프트 키워드라 부른다.
- 클래스 앞에 있을 땐 특별한 의미를 가지지만 다른 곳에서는 이름에 사용한다.
- 반면 class는 키워드 이다.
- when 사용 시, 각 분기에
break;를 넣지 않음. - when 한 분기 조건 내에 콤마로 분리해 여러개 사용 가능.
- when 분기 조건에서 임의 객체도 사용 가능, 조건에 식도 넣을 수 있다.
- when 에 아무 인자가 없으려면, 조건이 Boolean 결과를 계산하는 식이어야 함.
- 그 외에는 인자가 있어야 리턴이 가능.
- 타입 검사와 타입 캐스트를 조합할 수 있다.
is검사를 수행하면 굳이 변수를 원하는 타입으로 캐스팅 하지 않아도 됨. (실제로는 컴파일러가 수행함 → “스마트 캐스트”)- 해당 코드가 자바에서는 어떻게 동작하는 지 트랜스컴파일 해서 보아야 어떻게 동작하는 지 알 수 있다.
- 원하는 타입으로 명시적으로 타입 캐스트 하려면
as키워드를 사용한다.
- if나 when 모두 분기에 블록을 사용할 수 있다.
- 블록의 맨 마지막에 결과 값을 위치시키면 알아서 반환된다.
- 식이 본문인 함수는 블록을 본문으로 가질 수 없고, 블록이 본문인 함수는 내부에 return문이 반드시 있어야 한다.
fun expr(c1:Int, c2: Int) = when() … ==fun expr(c1:Int, c2: Int) { … return … }
이터레이션: while & for
1..10과 같이 시작과 끝 값을 콤마 2개로 연결해서 범위를 생성함.- 항상 끝 값을 포함한다.
- 끝 값을 포함하지 않으려면
until함수를 사용한다.for(x in 0 until size)와 같이 사용.for(x in 0..size-1)과 같은 의미.
100 downTo 1은 역방향 수열을 만든다.- 뒤에
step 2를 붙이면 증가값이 2로 바뀐다.
- 뒤에
c in 'a'..'z'와 같은 문자열 범위에서는 표준 라이브러리에 의해'a' <= c && c <= 'z'로 변환된다.in과!in이터레이션은 when 식에서도 사용할 수 있다.in연산자는 값이 범위 안에 속하는지 항상 결정할 수 있다.
예외처리
- 코틀린에서
throw는 식이므로 다른 식에 포함될 수 있다. - throws절이 코드에 없다. 함수가 던질 수 있는 예외를 따로 선언 하지 않아도 된다.
- 자바에서는
checked exception을 명시적으로 처리해야 한다. - 코틀린은
checked exception과unchecked exception을 따로 구분하지 않는다.
- 자바에서는
- 자바에서는 catch절에서 여러개의 에러를 받아 처리할 수 있는데, 코틀린은 지원하지 않는다.
- 최상위 에러를 받거나, 내부에서 which를 통해 분기 처리를 해주어야 한다.
3장. 함수의 정의와 호출
컬렉션
- 코틀린은 자신만의 컬렉션 기능을 제공하지 않는다.(기존 자바 컬렉션을 활용한다.)
hashMapOf(1 to “one”)과 같이 컬렉션 구성이 가능.to는 일반 함수다.
함수 호출을 쉽게하기
- 제네릭 함수의 문법은 자바와 비슷하다.
- 함수를 호출할 때, 함수에 전달하는 인자 중 일부의 이름을 명시할 수 있다.
- 디폴트 파라미터 값은 함수를 호출하는 쪽이 아닌, 함수 선언 쪽에 지정된다.
- 최상위 수준에 위치한 함수를 통해 불필요한 임포트를 제거한다.
- 프로퍼티 또한 최상위 위치에 놓아 불필요한 임포트를 제거한다.
- 접근자 메서드를 통해 노출된다. (val → getter / var → getter & setter )
- const 변경자를 통해 public static final 필드로 만들 수 있다.
확장 함수와 확장 프로퍼티
- 확장함수; 어떤 클래스의 멤버 메서드 처럼 호출하지만, 해당 클래스 밖에 선언된 함수
- 추가하려는 함수 앞에 확장 클래스의 이름을 붙인다; 수신 객체 타입
- 확장함수가 호출되는 대상이 되는 값; 수신 객체
fun String.lastChar(): Char = this.get(this.length - 1)String: 수신객체타입this: 수신 객체
- 확장함수 본문에서는 this 생략이 가능하다.
- 호출하는 쪽에서는 확장 함수와 멤버 메서드를 구분할 수 없지만, 중요하지 않다.(신경안씀)
as키워드를 통해 임포트한 것을 다르게 명시적으로 지정 가능.- 확장함수는 오버라이드 할 수 없다.
- 확장함수 호출 시, 수신 객체로 지정한 변수의 정적 타입에 의해 어떤 확장 함수를 호출할 지 결정됨. 변수에 저장된 객체의 동적 타입에 의해 결정되지 않음.
- 확장프로퍼티 선언 시,
getter()는 꼭 정의해주어야 한다.
컬렉션 처리
- 가변 길이 인자
- 호출 시, 인자 개수가 달라질 수 있는 함수를 정의
- 가변인자 앞에
*를 붙이기만 하면 된다.
- 중위 함수 호출
- 인자가 하나뿐인 메서드를 간편하게 호출
- 수신 객체와 유일한 메서드 인자 사이에 넣는다.
- 파라미터의 개수가 제한되는 단점.
- 그렇게 많이 사용하지 않음.
예시
infix fun <A, B> A.and(value: B) = Pair(this, value) infix fun <A, B, C> Pair<A, B>.and(value: C) = Triple(this.first, this.second, value) infix fun <A, B, C, D> Triple<A, B, C>.and(value: D) = Fourth(this.first, this.second, this.third, value) infix fun <A, B, C, D, E> Fourth<A, B, C, D>.and(value: E) = Fifth(this.first, this.second, this.third, this.fourth, value) data class Fourth<out A, out B, out C, out D>( val first: A, val second: B, val third: C, val fourth: D, ) data class Fifth<out A, out B, out C, out D, out E>( val first: A, val second: B, val third: C, val fourth: D, val fifth: E, )
- 구조 분해 선언
- 복합 값을 분해해 여러 변수에 나눌 수 있음
- 사이에 낀 중위 호출 값을 타고 들어가면, 특정 함수의 정의를 줄인 코드인 것을 알 수 있다.
문자열과 정규식
- 코틀린 문자열 = 자바 문자열
- 정규식을 명시적으로 생성이 가능하다.
- 3중 따옴표를 통해 줄 바꿈 있는 텍스트를 문자열로 만들 수 있다.
- 테스트에 좋다.
- HTML도 가능하다.
- 복잡하게 이스케이프 문을 안써도 된다.
로컬 함수와 확장
- 함수에서 추출한 함수를 원 함수 내부에 중첩시킬 수 있다.
- 코드의 중복을 제거한다.
- 로컬 함수는 자신이 속한 바깥 함수의 모든 파라미터와 변수를 사용할 수 있다.
객체.멤버처럼 수신 객체를 지정하지 않고도 공개된 멤버 프로퍼티나 메서드에 접근할 수 있다.유틸 클래스에서 주로 사용.
const val yyyyMMdd = "yyyyMMdd" const val formattedDateTime = "yyyy-MM-dd HH:mm:ss" const val openSearchDate = "YYYY-MM-dd'T'HH:mm:ss.SSS" val yyyyMMddDateTimeFormatter: DateTimeFormatter = DateTimeFormatter.ofPattern(yyyyMMdd) val dateTimeFormatter: DateTimeFormatter = DateTimeFormatter.ofPattern(formattedDateTime) val openSearchDateFormatter: DateTimeFormatter = DateTimeFormatter.ofPattern(openSearchDate) fun LocalDate.yyyyMMdd(): String { return format(yyyyMMddDateTimeFormatter) } fun LocalDateTime.openSearchDateTimeFormat(): String = this.format(openSearchDateFormatter)
4장. 클래스, 객체, 인터페이스
클래스 계층 정의
인터페이스
- 추상 메서드, 구현 메서드 정의 가능하나 상태(필드)가 들어갈 수 없다.
:를 붙이고 인터페이스와 클래스 이름을 적는 것으로 확장과 구현을 모두 처리한다. (클래스는 오직 하나만 확장 가능하다)override변경자를 꼭 사용해야 한다.- 코틀린 컴파일러는 구현을 하위 클래스에 직접 구현하도록 강제한다.
open, final, abstract 변경자 : 기본적으로 final
sealed: 클래스의 상속을 제한- 코틀린의 클래스와 메서드는 기본적으로
final, 상속을 허용하려면open변경자를 붙인다. (메소드, 프로퍼티 동일) - 오버라이드 하는 메서드의 구현을 하위 클래스에서 막으러면
final을 명시한다. - 추상 클래스는 인스턴스화 할 수 없다. 추상 멤버는 항상 열려있다.
| 변경자 | 해당 변경자가 붙은 멤버는 | 설명 |
|---|---|---|
| final | 오버라이드 X | 클래스 멤버의 기본 변경자다. |
| open | 오버라이드 O | 반드시 open을 명시해야 가능하다. |
| abstract | 반드시 오버라이드 해야 함. | 추상 클래스의 멤버에만 이 변경자를 붙일 수 있다. 추상 멤버에는 구현이 불가하다. |
| override | 상위 클래스나 상위 인스턴스의 멤버를 오버라이드 하는 중. | 오버라이드 하는 멤버는 기본적으로 열려있다. 하위 클래스의 오버라이드를 금지하려면 final을 명시한다. |
가시성 변경자 : 기본적으로 공개
internal: 같은 모듈 안에서만 볼 수 있다. 최상위 선언도 마찬가지.protected: 하위 클래스 안에서만 볼 수 있다. 최상위 선언은 불가능.private: 같은 클래스 안에서만 볼 수 있다. 최상위 선언은 같은 파일 안에서만 볼 수 있다.protected: 어떤 클래스나 그 클래스를 상속한 클래스 안에서만 보인다.- 해당 클래스를 확장한 함수는 접근 불가능하다.
- 코틀린에서는 외부 클래스가 내부 클래스나 중첨 클래스의
private멤버에 접근할 수 없다.
내부 클래스와 중첩 클래스 : 기본적으로 중첩 클래스
- 명시적으로 요청하지 않는 한, 바깥쪽 클래스 인스턴스에 대한 접근 권한이 없다.
- 내부 클래스에서 바깥쪽 클래스
Outer의 참조에 접근하려면this@Outer라고 써야 한다.
봉인된 클래스 : 클래스 계층 정의 시 계층 확장 제한
sealed변경자를 붙이면 그 상위 클래스를 상속한 하위 클래스 정의를 제한한다.- 해당 클래스의 하위 클래스르 정의할 때는 반드시 상위 클래스 안에 중첩시켜야 한다.
생성자와 프로퍼티를 갖는 클래스 선언
- 주 생성자, 부 생성자로 나뉘며 초기화 블록을 통해 초기화 할 수 있다.
클래스 초기화 : 주 생성자와 초기화 블록
constructor: 주 생성자나 부 생성자 정의 시작할 때 사용.init: 초기화 블록을 시작한다.- 생성자 파라미터 내
_는 프로퍼티와 생성자 파라미터를 구분하기 위해 사용. - 프로퍼티를 초기화 하는 식이나, 초기화 블록 내에서만 주 생성자의 파라미터를 참조할 수 있다.
- 주 생성자의 파라미터로 프로퍼티를 초기화 한다면, 앞에 val을 추가하는 방식으로 정의와 초기화를 간략화.
- 기반 클래스 초기화 시, 이름 뒤에 괄호를 치고 생성자 인자를 넘긴다.
부 생성자 : 상위 클래스를 다른 방식으로 초기화
- 클래스에 주 생성자가 없으면 모든 부 생성자는 반드시 상위 클래스를 초기화 하거나, 다른 생성자에게 위임해야 한다.
인터페이스에 선언된 프로퍼티 구현
- 인터페이스에 추상 프로퍼티 및 Getter & Setter가 있는 프로퍼티를 선언할 수 있다.
- 대신, 뒷받침하는 필드를 참조할 수 없다.
- 추상프로퍼티는 오버라이드 해야 하고, Getter & Setter가 있는 프로퍼티는 상속할 수 있다.
Getter와 Setter에서 뒷받침 하는 필드에 접근
field식별자를 통해 필드에 접근이 가능하다.field를 이용하지 않는 접근자 구현 정의 시, 뒷받침 하는 필드는 존재하지 않는다.
접근자의 가시성 변경
- 가시성 변경자를 앞에 추가해 변경할 수 있다.
컴파일러가 생성한 메서드 : 데이터 클래스와 클래스 위임
data클래스를 사용하면 컴파일러가 자동으로 메서드를 생성한다.by키워드를 통한 클래스 위임 패턴을 통해 불필요한 코드를 줄일 수 있다. (구현하고자 하는 것만 구현하고 나머지는 원래 또는 다른 객체에 위임)
Object 키워드 : 클래스 선언과 인스턴스 생성
객체 선언 : 싱글턴 쉽게 만들기
- 객체 선언 기능을 통해 싱글턴을 기본 지원
- 생성자는 객체 선언에 쓸 수 없다.
동반 객체 : 팩토리 메서드와 정적 멤버가 들어갈 장소
- 클래스의 인스턴스와 관계 없이 내부 정보에 접근해야 하는 함수가 필요할 때는 중첩 객체 선언의 멤버 함수로 정의해야 한다.
- 동반 객체는 바깥 클래스의
private생성자도 호출할 수 있다. - 하지만, 클래스를 확장해야 하는 경우에는 동반 객체 멤버를 하위 클래스에서 오버라이드 할 수 없으므로 여러개의 생성자를 사용하는게 낫다.
동반 객체를 일반 객체 처럼 사용
- 동반 객체는 클래스 안에 정의된 일반 객체다.
- 동반 객체에서 인터페이스 구현이 가능하다.
- 동반 객체 내부에 함수를 정의함으로써 클래스에 대해 호출할 수 있는 확장함수를 생성할 수 있다. (실제로는 멤버함수가 아니다)
객체 식 : 무명 내부 클래스를 다른 방식으로 작성
- 무명 객체를 정의할 때도
object키워드를 사용한다. - 여러 인터페이스를 구현하거나 클래스를 확장하면서 인터페이스를 구현할 수 있다.
자주 사용하는 것
- Abstract
- JPA base entity
- Jpa 에서는 데이터 클래스를 사용하면 기본적으로 구현해주는 것은 편하지만 일대다나 다대다 관계에서 사이클링 구조가 발생하기도 한다.
- 약간 호불호 갈리는 느낌
- Data class
- 상속 불가, final이 기본
- JPA base entity
- Class
- Interface
- 타입 캐스팅을 하기 위해 enum 인터페이스 사용하여 직렬화, 역직렬화 할 때 사용
- Constructor 는 많이 안쓴다
5장. 람다로 프로그래밍
람다 식과 멤버 참조
람다 소개 : 코드 블록을 함수 인자로 넘기기
- 코드 블록을 함수 인자로 넘길 수 있다.
람다와 컬렉션
- 코틀린에서는 컬렉션 처리에 라이브러리 함수를 자주 사용한다.
람다 식의 문법
- 람다 식을 변수에 저장할 수 있다. 화살표(
→)가 인자 목록과 람다 본문을 구분한다. - 코틀린 람다 호출에는 아무 부가 비용이 없으며, 프로그램의 기본 구성 요소와 비슷한 성능을 낸다.
- 컴파일러가 유추할 수 있는 인자 타입은 굳이 안적어도 된다.
- 람다 파라미터 이름을 따로 지정하지 않은 경우에만
it키워드가 자동으로 만들어 진다. - 람다를 변수에 저장할 때는 파라미터 타입을 명시해야 한다.
현재 영역에 있는 변수에 접근
- 코틀린 람다 안에서는 파이널 변수가 아닌 변수에 접근이 가능하며, 람다 안에서 바깥의 변수를 변경해도 된다.
- 람다가 안에서 사용하는 외부 변수를 람다가 포획한 변수(capture)라고 한다.
- 람다에서 시작하는 모든 참조가 포함된 닫힌(closed) 객체 그래프를 람다 코드와 저장해야 하는데 이런 구조를 클로저(closure)라고 부른다.
- 포획한 변수가 있는 람다를 저장해서 함수가 종료되어도, 본문 코드는 여전히 포획한 변수를 읽거나 쓸 수 있다.
- 파이널이 아닌 변수를 래퍼로 감싸서 나중에 변경 가능하게 하고 해당 참조를 람다와 함께 저장한다. (final 이냐 아니냐에 따라 변경 불가능/가능이 결정된다.)
- 람다를 이벤트 핸들러나 다른 비동기적으로 실행 되는 코드로 활용하는 경우, 함수 호출이 끝난 다음에 로컬 변수가 변경될 수 있다. (순서가 바뀜)
멤버 참조
- 넘기려는 코드가 이미 함수인 경우, 이중 콜론
::를 사용하며, 이를 멤버 참조라고 한다. - 참조 대상이 함수인지 프로퍼티인지 관계 없이 멤버 참조 뒤에는 괄호를 넣으면 안된다.
- 생성자 참조를 통해 람다를 정의하지 않고 위임할 수 있다.
val person = ::Person - 호출 시, 수신 대상 객체를 별도로 지정해 줄 필요가 없다.
컬렉션 함수형 API
Filter & map
- Java Stream과 비슷, 람다식으로 바로 받음.
all, any, count, find : 컬렉션에 술어 적용
!all과 그 조건의 부정에 대해any를 수행한 결과는 같다. (드모르강법칙)any를 사용하려면 술어를 부정해야 한다.
groupBy : 리스트를 여러 그룹으로 이뤄진 맵으로 변경
- 특성을 파라미터로 전달하면 컬렉션을 자동으로 구분한다.
flatMap과 flatten : 중첩된 컬렉션 안의 원소 처리
flatMap은 람다를 컬렉션의 모든 객체에 적용하고 람다를 적용한 결과 얻어지는 여러 리스트를 한데로 모은다.- 특별히 변환이 필요없다면,
flatten()를 사용하여 펼친다.
지연 계산(lazy) 컬렉션 연산
- 시퀀스(sequence)를 사용하면 중간 임시 컬렉션을 사용하지 않고도 컬렉션 연산을 연쇄할 수 있다.
- 자바 스트림과 비슷해서 찾아보았는데, 비교 글을 찾았다. (https://bcp0109.tistory.com/359)
- 자바 스트림에서는 기본적으로 지연 계산을 통해 불필요 연산을 최소화.
- 코틀린 컬렉션에서는 그냥 사용하면 전체 연산이 적용됨.
- 따라서, 시퀀스를 통해 사용하면 지연 계산을 하게되어 좋음.
- 그러나 오버헤드가 있어 상황에 맞게 사용해야 한다.
asSequence확장 함수를 호출하면 어떤 컬렉션이든 시퀀스로 변경할 수 있다.
시퀀스 연산 실행 : 중간 연산과 최종연산
- 중간 연산은 다른 시퀀스를 반환, 최종 연산은 결과를 반환한다.
- 시퀀스에 대한
map과filter는 각 원소에 대해 순차적으로 적용된다.- 연산을 차례대로 적용하다가 결과가 얻어지면 그 이후 원소에 대해서는 작업하지 않음.
시퀀스 만들기
- 컬렉션에 대해
asSequence를 사용하여 생성한다.
자바 함수형 인터페이스 활용
- 무명 클래스 인스턴스 대신 람다를 넘길 수 있다.
- 이게 가능한 이유는 추상 메서드가 단 하나만 있는 경우 동작한다. 이런 인터페이스를
함수형 인터페이스또는SAM 인터페이스라고 한다. (단일 추상 메서드)
- 이게 가능한 이유는 추상 메서드가 단 하나만 있는 경우 동작한다. 이런 인터페이스를
자바 메서드에 람다를 인자로 전달.
- Runnable 타입의 파라미터를 받을 때, 컴파일러는 자동으로 람다를 Runnable 인스턴스로 변환해준다.
- 자바에서는 객체를 명시적으로 선언하는 경우 메서드를 호출할 때마다 새로운 객체가 생성된다.
- 람다에서는 정의가 들어있는 함수의 변수에 접근하지 않는 람다에 대응하는 무명 객체를 메서드 호출할 때 마다 반복 사용 한다.
SAM 생성자 : 람다를 함수형 인터페이스로 명시적으로 변경
- SAM 생성자는 인터페이스의 유일한 추상 메서드의 본문에 사용할 람다만을 인자로 받아서 함수형 인터페이스를 구현하는 클래스의 인스턴스를 반환한다.
- 람다에는 무명 객체와 달리 인스턴스 자신을 가리키는
this가 없다.
수신 객체 지정 람다 : with 와 apply
with는 어떤 객체의 이름을 반복하지 않고도 그 객체에 대한 다양한 연산을 수행한다.- with에게 인자로 넘긴 객체의 클래스와 with를 사용하는 코드가 들어있는 클래스 안에 이름이 같은 메서드가 있으면? → this 참조앞에 레이블을 붙이면 구분할 수 있다.
- 바깥쪽 클래스에 정의된 걸 호출하고 싶다? →
this@OuterClass.toString()과 같이 사용한다.
- 람다의 결과 대신 수신 객체가 필요한 경우
apply를 사용한다. with와 거의 같지만, 차이점은 항상 자신에게 전달된 객체(수신 객체)를 반환한다는 것이다.apply는 확장 함수로 정의되어 있다. 객체의 인스턴스를 만들면서 즉시 프로퍼티 중 일부를 초기화 해야하는 경우 유용하다.buildString이라는 함수를 사용하면StringBuilder객체와toString호출을 알아서 해준다.
6장.코틀린 타입 시스템
널 가능성(nullability)
- 실행 시점에서 컴파일 시점으로 널 접근을 옮기는 것.
널이 될 수 있는 타입
- 프로그램 안의 프로퍼티나 변수에 null을 허용하게 만드는 것.
- NPE가 발생할 수 있는 호출 자체를 금지한다.
- 타입 뒤에
?를 붙이면 null을 저장할 수 있다는 뜻- 널이 될 수 있는 타입인 변수에 대해
변수.메소드()처럼 메소드를 직접 호출할 수 없다. - 널이 될 수 있는 값을 널이 될 수 없는 타입의 변수에 대입할 수 없다.
- 널이 될 수 있는 타입의 값을 널이 될 수 없는 타입의 파라미터를 받는 함수에 전달할 수 없다.
- 널이 될 수 있는 타입인 변수에 대해
- null 자체와 비교하게되면 컴파일러는 그 사실을 기억하고, null이 아님이 확실한 영역에서는 해당 값을 널이 될 수 없는 타입처럼 사용한다.
타입의 의미
- 자바에서는 널 여부를 추가 검사하기 전 까지는 변수에 대해 어떤 연산을 할 지 모른다.
- 코틀린에서는 이런 문제에 대해 종합적인 접근 방식을 제공한다.
안전한 호출 연산자: ?.
?.는 null 검사와 메서드 호출을 한 번의 연산으로 수행한다.s?.toUpperCase()==if (s != null ) s.toUpperCase() else null- 안전한 호출을 연쇄하여 사용할 수 있다.
?.address?.country
엘비스 연산자: ?:
- 엘비스(elvis) 혹은 널 복합(null coalescing)이라고 함.
- 이항 연산자로 좌항을 계산한 값이 널인지 검사하여 아니면 좌항을 널이면 우항 값을 결과로 한다.
return이나throw등의 연산도 식이기 때문에 엘비스 연산자에 적용 가능하다.
안전한 캐스트: as?
- 자바에서는 as로 지정한 타입으로 바꿀 수 없으면
ClassCastException이 발생한다. - 어떤 값을 지정한 타입으로 캐스트 한다. 변환할 수 없으면 null을 반환한다.
널 아님 단언: !! - 컴파일러에게 알려주기.
- 느낌표를 이중으로 사용하여 어떤 값이든 널이 될 수 없는 타입으로 강제로 바꿀 수 있다.
- 컴파일러에게 나는 이 값이 null이 아님을 잘 알고 있다. 내가 잘못 생각했으면 예외가 발생해도 감수하겠다의 의미이다.
- 호출된 함수가 언제나 다른 함수에서 널이 아닌 값을 전달 받는다는 사실이 분명하다면 굳이 널 검사를 더 안해도 될 때 단언을 사용한다.
!!를 사용하게 되면 스택 트레이스에서 몇번째 라인에서 에러 나는지 안나오기 때문에 같이 한 줄에 쓰지말 것.
let 함수
- 모든 객체가 확장함수로 가지고 있다.
- 원하는 식을 평가해서 결과가 널인지 검사한 다음, 그 결과를 변수에 넣는 작업을 간단하게 처리할 수 있다.
- let 함수는 자신의 수신 객체를 인자로 전달받은 람다에게 넘긴다.
email?.let { email → sendEmailTo(email) } - 긴 식의 결과를 따로 저장하는 변수 만들지 않고 로직을 구현할 수 있다.
- let 호출 중첩이 가능하다.
나중에 초기화할 프로퍼티
- 코틀린에서는 일반적으로 생성자에서 모든 프로퍼티를 초기화 해야 한다.
- 널이 될 수 있는 타입을 사용하면 모든 프로퍼티 접근에 널 검사를 넣거나
!!연산자를 써야 한다.- 이를 해결하기 위해 late-initialized를 사용한다.
- 나중에 초기화 할 프로퍼티는 항상
var여야 한다.- 생성자 안에서 초기화 할 필요가 없다.
private lateinit var myService: MyService와 같이 사용한다.
널이 될 수 있는 타입 확장
- 직접 변수에 대해 메서드를 호출해도 확장 함수인 메서드가 알아서 NULL을 처리해준다.
isNullorEmpty혹은isNullOrBlank와 같은 메서드가 있다.
- 널이 될 수 있는 타입에 대한 확장을 정의하면 널이 될 수 있는 값에 대해 그 확장함수를 호출 할 수 있다.
- 코틀린에서는 널이 될 수 있는 타입의 확장함수 안에서는
this가 널이 될 수 있다. (자바와 다른점)
타입 파라미터의 널 가능성
- 모든 타입 파라미터는 기본적으로 널이 될 수 있다.
fun <T> - 파라미터는 널이 될 수 있는 타입을 표시하려면 반드시 물음표를 타입 이름 뒤에 붙여야 한다
- 타입 파라미터는 이 규칙에 대한 유일한 예외다.
- 파라미터가 널이 아님을 확실히 하려면 타입 상한을 지정해야 한다.
fun <T: Any>이렇게 하면 널이 될 수 있는 값을 거부한다.
널 가능성과 자바
- 자바 코드의
@NotNull,@Nullable과 같은 정보를 코틀린에서도 활용한다. - 이런게 없는 경우 아래와 같은 타입이 된다.
플랫폼 타입
- 코틀린이 널 관련 정보를 알 수 없는 타입
- 모든 연산의 책임은 개발자에게 있다.
- 플랫폼 타입은 널이 될 수 있는 타입이나 널이 될 수 없는 타입 모두 사용가능하다.
- 코틀린 컴파일러는 공개 가시성인 코틀린 함수의 널이 아닌 타입인 파라미터와 수신 객체에 대한 널 검사를 추가해준다.
상속
- 코틀린에서 자바 메서드를 오버라이드 할 때 그 메서드의 파라미터와 반환 타입을 널이 될 수 있는 타입으로 선언할 지 널이 될 수 없는 타입으로 선언할 지 결정해야 한다.
코틀린의 원시타입
코틀린은 원시타입과 래퍼타입을 구분하지 않는다.
원시타입 : Int, Boolean 등
- 코틀린은 원시타입과 래퍼타입을 구분하지 않으므로, 항상 같은 타입을 사용한다.
- 숫자 타입 등 원시 타입의 값에 대해 메서드를 호출할 수 있다.
- 실행 시점에 해당 타입들은 가능한 효율적인 방식으로 표현된다.
- 자바에서 상응하는 원시 타입으로 컴파일 할 수 있다.
널이 될 수 있는 원시 타입 : Int?, Boolean? 등
- 널 참조를 자바의 참조 타입의 변수에만 대입할 수 있기 때문에 널이 될 수 있는 코틀린 타입은 자바 원시 타입으로 표현할 수 없다.
- 코틀린에서 널이 될 수 있는 원시 타입을 사용하면 자바의 래퍼 타입으로 컴파일된다.
- 널인지 아닌지 검사를 하고 나서야 일반적으로 값을 다룰수 있다.
- 제네릭 클래스의 경우 래퍼 타입을 사용한다.
- 자바나 코틀린 모두 제네릭 클래스는 항상 박스 타입을 사용해야 한다.
숫자 변환
- 예상치 못한 동작을 피하기 위해 다른 타입의 숫자로 자동변환이 되지 않는다.
- 대신, 직접 변환 메서드를 호출해야 한다.
- 모든 원시 타입(Boolean 제외)에 대한 변환 함수를 제공한다.
- 숫자 리터럴의 경우에는 보통 변환 함수를 호출할 필요가 없다.
Any, Any? : 최상위 타입
- 자바에서는
Object가 클래스 계층의 최상위 인 것 처럼 코틀린에서는Any타입이 모든 널이 될 수 없는 타입의 조상이다. - 자바에서는
Object가 필요한 경우, 원시 타입을 래퍼 타입으로 감싸야 하지만 코틀린에서는 원시타입을 포함한 모든 타입의 조상 타입이다. - Kotlin’s
Any== Java’sObject
Unit 타입 : 코틀린의 Void
Unit은 모든 기능을 갖는 일반 타입이며 타입 인자로 쓸 수 있다.- 제네릭 파라미터를 반환하는 함수를 오버라이드 하면서 반환 타입으로 사용할 때 유용하다.
Nothing 타입: 이 함수는 결코 정상적으로 끝나지 않는다
- 반환 값이라는 개념 자체가 의미 없는 일부 함수가 존재한다.(테스트 라이브러리 등)
- Nothing 타입은 아무 값도 포함하지 않는다. 따라서, 함수의 반환 타입이나 반환 타입으로 쓰일 타입 파라미터로만 사용된다.
컬렉션과 배열
널 가능성과 컬렉션
타입 인자의 널 가능성은 타입 시스템 일관성을 지키기 위해 필수적으로 고려해야 한다.
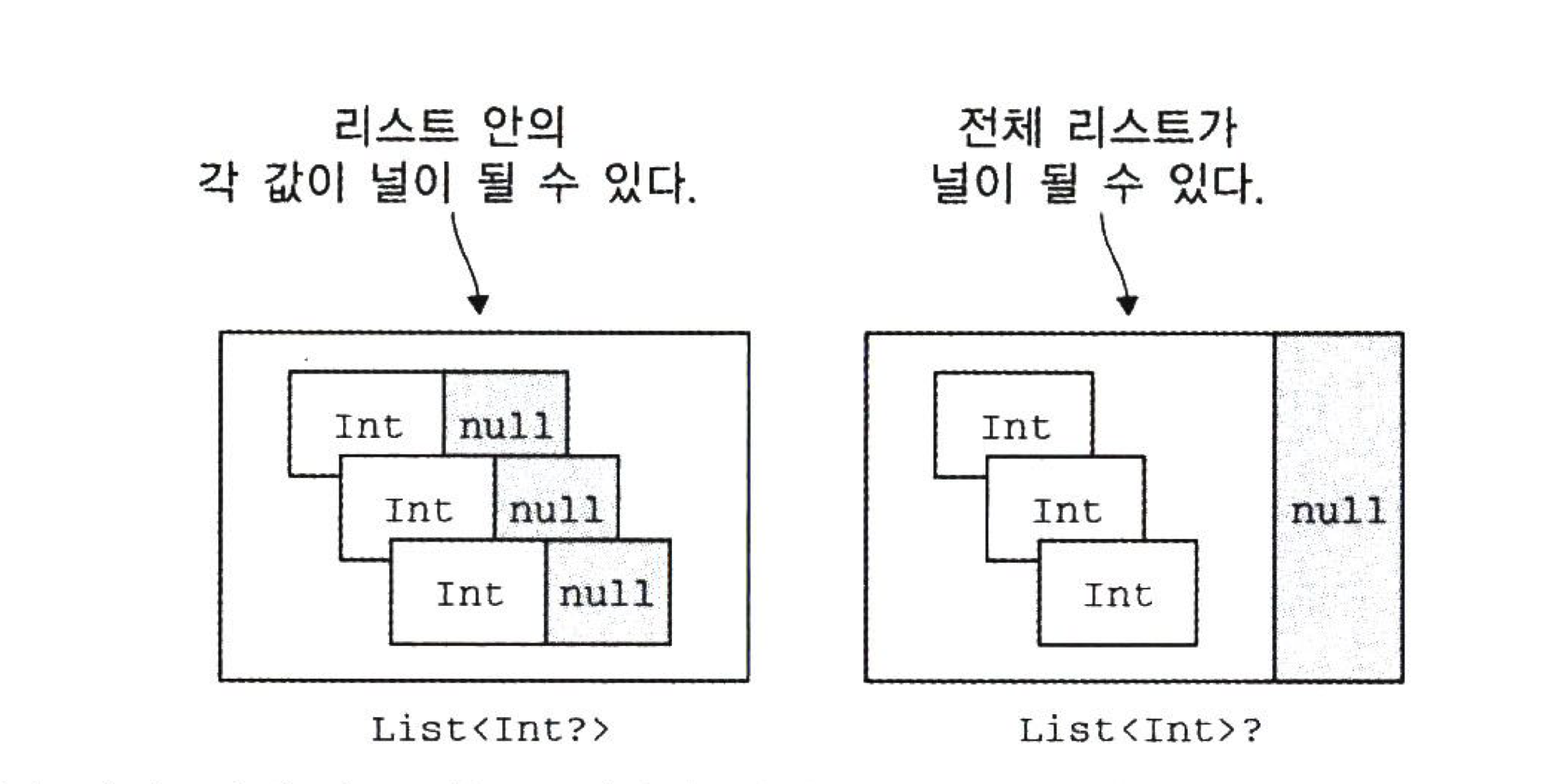
- 타입 인자로 쓰인 타입에도 같은 ? 표시를 사용할 수 있다.
- 원소의 널 가능성이 존재한다면 산술식에 사용하기 전에 널 여부를 검사해야 한다.
읽기 전용과 변경가능한 컬렉션
- 코틀린에서는 컬렉션 안을 접근하는 인터페이스(Collection)와 내부 데이터를 변경하는 인터페이스(MutableCollection)가 분리되어있다.
- MutableCollection은 Collection을 확장하면서 내용을 변경하는 메서드를 더 제공한다.
- 항상 읽기 전용 인터페이스를 사용하는 것을 규칙 삼아 변경 필요가 있을 때만 변경 가능한 버전을 사용하라.
- 프로그램에서 데이터에 어떤 일이 벌어지는 지를 더 쉽게 이해하기 위함이다.
- 읽기 전용 컬렉션이라고 꼭 변경 불가능한 컬렉션일 필요는 없다.
- 다만, 읽기 전용 컬렉션이 항상 스레드 세이프하지 않다는 점을 명심해야 한다.
코틀린 컬렉션과 자바
- 모든 코틀린 컬렉션은 그에 상응하는 자바 컬렉션 인터페이스의 인스턴스이다. 즉, 변환할 필요가 없다.
코틀린은 모든 자바 컬렉션 인터페이스마다 읽기 전용과 변경 가능한 인터페이스를 제공한다.

- 컬렉션을 변경하는 자바 메서드에 읽기 전용 Collection을 넘겨도 코틀린 컴파일러는 이를 막을 수 없다.
- 따라서, 파라미터를 넘기는 책임은 사용자에게 있다.
컬렉션을 플랫폼 타입으로 다루기
- 컬렉션 타입이 시그니처에 들어간 자바 메서드 구현을 오버라이드 하려는 경우 읽기 전용이냐 변경 가능이냐 차이에 문제가 있다.
- 오버라이드 하려는 메서드의 자바 컬렉션 타입을 어떤 코틀린 컬렉션 타입으로 표현할지 결정해야 한다.
- 컬렉션이 널이 될 수 있는가?
- 컬렉션의 원소가 널이 될 수 있는가?
- 오버라이드 하는 메서드가 컬렉션을 변경할 수 있는가?
- 기본적으로 배열보다는 컬렉션을 더 먼저 사용해야 한다. 그러나 자바 API가 여전히 배열을 사용하므로 배열 사용하는 경우가 생긴다.
객체의 배열과 원시 타입의 배열
- 코틀린 배열은 타입 파라미터를 받는 클래스다. 배열의 원소타입은 그 타입 파라미터에 의해 정해진다.
- 배열을 만드는 방법
arrayOf함수에 원소를 넘긴다.arrayOfNulls함수에 정수 값을 인자로 넘기면 모든 원소가 null 이고 인자로 넘긴 값과 크기가 같은 배열을 만든다.Array생성자는 배열 크기와 람다를 인자로 받아 람다를 호출해 배열 원소를 초기화 한다.
- 배열을 만드는 방법
- 데이터가 이미 컬렉션에 들어있다면 컬렉션을 배열로 변환해야 한다.
toTypedArray메서드를 사용해 쉽게 변경할 수 있다. - 배열 타입의 타입 인자도 항상 객체 타입이 된다.
- 원시 타입의 배열이 필요하다면 특별한 배열 클래스를 사용하는데, 코틀린은 각 원시타입마다 하나씩 제공한다.
- 원시 타입의 배열을 만드는 방법
- 각 배열 타입 생성자는 size 인자를 받아 해당 원시 타입의 디폴트 값으로 초기화된 배열을 반환한다.
- 팩토리 함수는 여러 값을 가변인자로 받아 배열을 반환한다.
- 람다를 인자로 받는 생성자를 사용한다.
- 원시 타입의 배열을 만드는 방법
- 변환함수(toIntArray)를 사용해 박싱하지 않은 값이 들어있는 배열로 변환할 수 있다.
7장. 연산자 오버로딩과 기타 관례
어떤 클래스안에 특별한 메서드를 정의하면 그 클래스의 인스턴스에 대해 + 연산자를 사용할 수 있다. 이를 관례라고 한다.
산술 연산자 오버로딩
이항 산술 연산 오버로딩
+→operator fun plus()⇒ 컴파일 시,a+b→a.plus(b)오버로딩이 가능한 이항 산술연산자
식 함수 이름 a * b times a / b div a % b mod(1.1부터 rem) a + b plus a - b minus - 교환 법칙은 지원 안함! (
a op b == b op a) - 연산자의 순서를 바꾸는 경우 함수도 그에 따라 바뀌어야 한다.
비트 연산자에 대한 함수 목록
함수 이름 설명 shl 왼쪽 시프트(자바 «) shr 오른쪽 시프트(부호 비트 유지, 자바 ») ushr 오른쪽 시프트(0으로 부호 비트 설정, 자바 »>) and 비트 곱(자바 &) or 비트 합(자바 ) xor 비트 배타 합(자바 ^) inv 비트 반전(자바 ~)
복합 대입 연산자 오버로딩
+=,-=등의 연산자를 지원한다.+=→plusAssign정의- 변경 불가능 하다면 새로운 값을 반환 하도록 연산 추가만 하고 변경 가능하다면
plusAssign이나 비슷한 연산을 제공해야 한다. (대상이 변경 가능/불가능이냐에 따라 제공되는 연산자 1개만 정의하도록 해야 한다.) +와-는 항상 새로운 컬렉션을 반환,+=또는-=는 변경을 적용한 복사본을 반환
단항 연산자 오버로딩
- 단항 연산자를 오버로딩 하는 경우 인자를 가지지 않는다.
| 식 | 함수 이름 |
|---|---|
| +a | unaryPlus |
| -a | unaryMinus |
| !a | not |
| ++a, a++ | inc |
| —a, a— | dec |
비교 연산자 오버로딩
동등성 연산자 : equals
- 코틀린에서는
==연산자를equals메서드 호출로 컴파일한다. !=연산자를 사용하는 식도equals호출로 컴파일 된다.- 널이 아닌 경우에만 호출, 널이라면 다른 값도 널인 경우에만
true다. - 식별자 비교(
===) 연산자는 자바==와 같다 equals함수는Any에 정의된 메서드 이므로override가 필요하다.- 확장 함수보다 순위가 높아 확장 함수로 정의가 불가능 하다.
순서 연산자 : compareTo
Comparable인터페이스 안에 있는compareTo호출로 컴파일 한다.
컬렉션과 범위에 대한 관례
인덱스로 원소에 접근 : get과 set
- 연산자를 사용해 읽는 연산은
get연산자 메서드로 변환. - 원소를 쓰는 연산은
set연산자 메서드로 변환. - 여러 파라미터를 사용하는
get을 정의할 수 있다.
in 관례
- 객체가 컬렉션에 들어있는지 검사 하며 대응 함수는
contains다.
rangeTo 관례
- 범위를 만들 때 사용하는
..구문은rangeTo함수에 대응된다. - 모든
Comparable객체에 대해 적용 가능한rangeTo함수가 들어있다.
for 루프를 위한 iterator 관례
iterator메서드를 확장 함수로 정의 가능 하다.CharSequence에 대한iterator확장 함수를 제공한다.
구조 분해 선언과 Component 함수
- 복합적인 값을 분해해서 여러 다른 변수를 한꺼번에 초기화 한다.
- 컴파일러가 자동으로
componentN함수를 생성한다. - 여러 값을 반환해야할 때 유용하다.
- 모든 값이 들어갈 데이터 클래스를 정의하고 함수의 반환 타입을 그 데이터 클래스로 바꾸는 식으로 사용한다.
- 표준 라이브러리의
Pair나Triple클래스를 사용한다.
구조 분해 선언과 루프
- 루프 안에서도 구조 분해 선언을 사용할 수 있다. (ex. Map … )
프로퍼티 접근자 로직 재활용: 위임 프로퍼티
위임 프로퍼티 소개
Delegate클래스의 인스턴스를 위임객체로 사용하며,by뒤에 있는 식을 계산해 위임에 쓰일 객체를 얻는다.- 컴파일러는 숨겨진 도우미 프로퍼티를 만들고 그 프로퍼티를 위임 객체의 인스턴스로 초기화 한다.
class Foo {
private val delegate = Delegate() // 컴파일러가 생성한 도우미 프로퍼티
var p: Type // 컴파일러가 생성한 접근자는 delegate의 getValue, setValue를 호출한다.
set(value: Type) = delegate.setValue(..., value)
get() = delegate.getValue(...)
}
위임 프로퍼티 사용: by lzay()를 사용한 프로퍼티 초기화 지연
- 변수 2개를 사용하여 리턴하는 뒷받침하는 프로퍼티 기법을 사용한다.
class Persons(val name: String) {
// 데이터를 저장하고 emails의 위임 객체 역할을 하는 프로퍼티
private var _emails: List<Email>? = null
val emails: List<Email>
get() {
if (_emails == null) {
// 최초 접근 시 이메일을 가져온다.
_emails = loadEmails(this)
}
// 저장해둔 데이터가 있으면 그걸 반환한다.
return _emails!!
}
private fun loadEmails(persons: Persons): List<Email>? {
return listOf(Email.ALICE, Email.JOHN)
}
}
enum class Email {
ALICE, JOHN
}
fun main() {
val p = Persons("Alice")
p.emails // load
p.emails // not load
}
lazy함수는 시그니처의getValue메서드가 들어있는 객체를 반환한다.by키워드와 함께 사용해 위임 프로퍼티를 만들 수 있다.
위임 프로퍼티 구현
getValue,setValue함수에도operator변경자가 붙는다.- 프로퍼티를 표현하는 객체를 파라미터로 받는다.
KProperty타입의 객체를 사용해 프로퍼티를 표현한다. by오른쪽에 오는 객체를 위임 객체라고 한다. 주 객체의 프로퍼티를 읽거나 쓸 때마다 위임 객체의get/setValue를 호출한다.
class Person5(val name: String, age: Int, salary: Int) : PropertyChangeAware() {
var age: Int by ObservableProperty2(age, changeSupport)
var salary: Int by ObservableProperty2(salary, changeSupport)
}
위임 프로퍼티 컴파일 규칙
- 컴파일러는 모든 프로퍼티 접근자 안에
getValue와setValue호출 코드를 생성해준다.
프로퍼티 값을 맵에 저장
- 확장 가능한 객체 : 자신의 프로퍼티를 동적으로 정의할 수 있는 객체
프레임워크에서 위임 프로퍼티 활용
object Users : IdTable() { // 객체는 데이터베이스에 저장되어있다고 가정
// 프로퍼티는 테이블 컬럼에 해당.
val name = varchar("name", length = 50).index()
val age = Integer("age")
}
// 각 User 인스턴스는 테이블에 들어있는 구체적인 엔티티이다.
class User(id: EntityID) : Entity(id) {
// 사요자 이름은 데이터베이스 컬럼에 들어가 있다
var name: String by Users.name
var age: Int by Users.age
}
- 프로퍼티에 접근할 때 자동으로
Entity클래스에 정의된 매핑으로부터 값을 가져오는 코드이다. - 각 엔티티 속성은 위임 프로퍼티이며, 컬럼 객체를 위임 객체로 사용한다.
8장. 고차 함수: 파라미터와 반환 값으로 람다 사용
고차 함수 정의
- 다른 함수를 인자로 받거나 함수를 반환하는 함수이다.
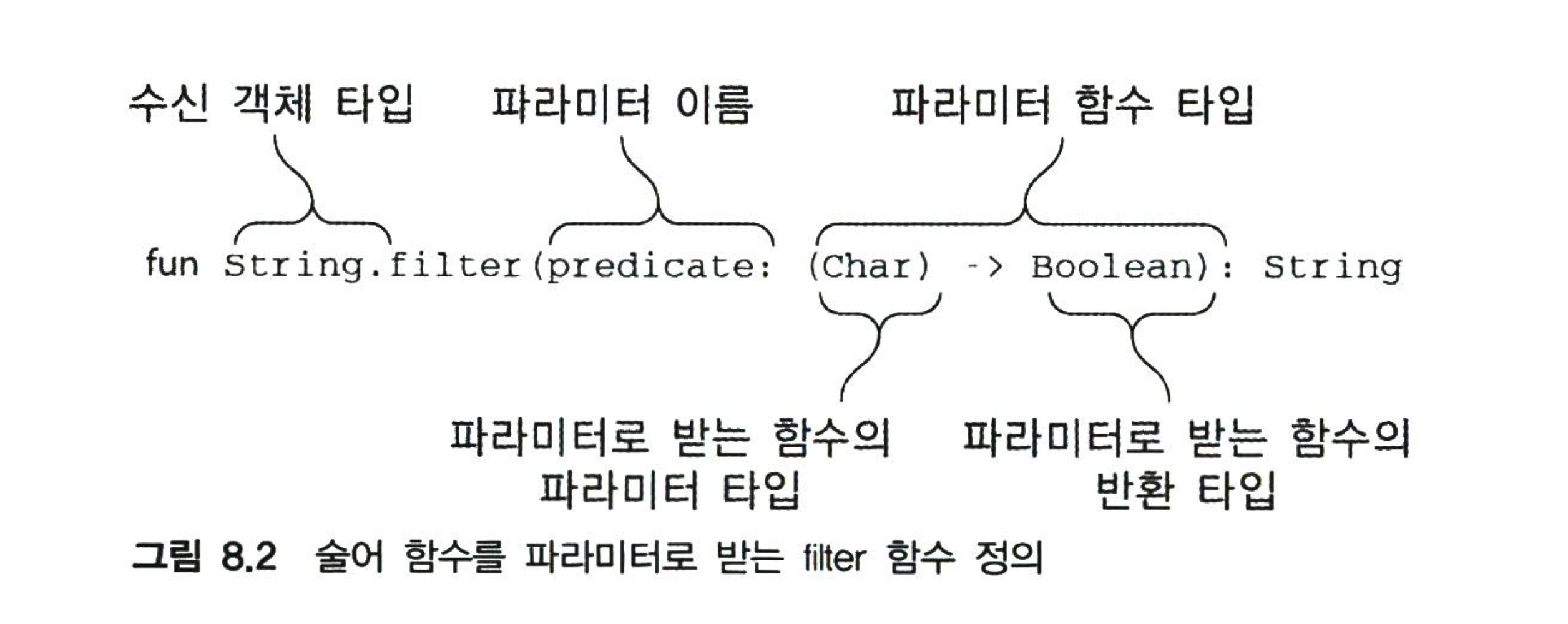
함수 타입
- 함수 타입을 정의하려면 함수 파라미터의 타입을 괄호안에 넣고, 그 뒤에 화살표를 추가한 다음 함수의 반환 타입을 지정한다.
(Int, String) → Unit - 함수 타입에서도 널이 될 수 있는 타입을 지정할 수 있다.
var canReturnNull: (Int, Int) → Int? = {x,y → null}: 반환 타입이 널이 될 수 있음.var funOrNull: ((Int,Int) -> Int)? = null: 함수 타입 전체가 널이 될 수 있음.
함수 타입에서 파라미터 이름을 지정할 수 있다.
fun performRequest( url: String, callback: (code: Int, content: String) -> Unit ...
인자로받은 함수 호출
- 고차 함수의 구조
자바에서 코틀린 함수 타입 사용
- 컴파일된 코드 안에서 함수 타입은 일반 인터페이스로 바뀐다. 즉, 함수 타입의 변수는 FunctionN 인터페이스를 구현하는 객체를 저장한다.
각 인터페이스에서는
invoke메소드 정의가 들어있어 이를 호출하면 함수를 실행할 수 있다.fun <T> Collection<T>.joinToString3( spearator: String = ", ", prefix: String = "", postfix: String = "", // 널이 될 수 있는 함수 타입의 파라미터 선언 **transform**: ((T) -> String)? = null ): String { val result = StringBuilder(prefix) for ((index, element) in this.withIndex()) { if (index > 0) result.append(spearator) // 안전 호출을 사용해 함수를 호출 한다. **val str = transform?.invoke(element)** // 엘비스 연산자를 사용해 람다를 인자로 받지 않은 경우를 처리한다. ?: element.toString() result.append(str) } result.append(postfix) return result.toString() }- 자바 8 람다를 넘기면 자동으로 함수 타입의 값으로 변환된다.
- 자바에서 코틀린 함수를 호출하는 경우 수신객체를 확장함수 첫번째 인자로 명시적으로 넘겨야 한다.
디폴트 값을 지정한 함수 타입 파라미터나 널이 될 수 있는 함수 타입 파라미터
- 디폴트 파라미터, 함수 타입에 대한 디폴트 값 선언도
=뒤에 람다를 넣으면 된다. - 널이 될 수 있는 함수 타입을 사용할 수 있는데, 그 함수를 직접 호출할 수는 없다. → NPE 가능성 때문에.
함수를 함수에서 반환
함수의 반환 타입으로 함수 타입을 지정한다.
// 여기서는 getShippingCostCalculator 파라미터는 delivery 타입이고 // Order 함수 타입 파라미터를 받아 Doble로 리턴하는 함수를 파라미터로 받아 리턴한다. fun getShippingCostCalculator(delivery: Delivery): (Order) -> Double { if(delivery == Delivery.EXPEDITED) { // 함수에서 람다를 반환한다. return { order -> 6 + 2.1 * order.itemCount} } return {order -> 1.2 * order.itemCount} } // ... main ... // 반환받은 함수를 변수에 저장한다. val calculator = getShippingCostCalculator(Delivery.EXPEDITED) // 반환받은 함수를 호출한다. println("Shipping costs ${calculator(Order(3))}")
람다를 활용한 중복 제거
- 고차함수에서 람다를 활용하여 코드의 중복을 제거한다.
- 디자인 패턴을 함수 타입과 람다 식을 사용해 단순화 할 수 있다.
- 전략 패턴의 경우 람다가 없다면 인터페이스를 선언하고 구현 클래스를 통해 전략을 정의한다.
- 함수 타입을 언어가 지원하면 일반 함수 타입을 사용해 표현하고, 경우에 따라 다른 람다 식을 넘김으로써 여러 전략을 전달할 수 있다.
인라인 함수: 람다의 부가 비용 없애기
- 람다 식의 특징
- 사용 시 새로운 클래스가 만들어지지 않는다.
- 람다가 변수를 포획하면 람다 생성 시점마다 새로운 무명 클래스 객체가 생긴다. → 무명 클래스 생성에 따른 부가 비용 발생
인라이닝이 작동하는 방식
- 어떤 함수를
inline으로 선언하면 그 함수의 본문이 인라인이 된다. - 함수를 호출하는 코드를 함수 호출 바이트코드 대신 함수 본문을 번역한 바이트코드로 컴파일 된다는 뜻이다.
람다 본문에 의해 생성된 바이트 코드는 람다를 호출하는 코드 정의의 일부분으로 간주되기 때문에 코틀린 컴파일러는 람다를 함수 인터페이스로 구현하는 무명 클래스로 감싸지 않는다.
fun __foo__(l: Lock) { println("Before Sync") l.lock() // synchronized(l) { // 컴파일 전 코드 // println("Action") // } try { println("Action") // 람다 코드의 본문이 인라이닝 된 코드 } finally { l.unlock() } println("After Sync") }- 한 인라인 함수를 두 곳에서 각각 다른 람다를 사용해 호출한다면 따로 인라이닝 된다.
인라인 함수의 한계
- 함수가 인라이닝 될 때, 그 함수에 인자로 전달된 람다 식의 본문은 결과 코드에 직접 들어간다.
- 이 방식으로 인해 함수가 파라미터로 전달받은 람다를 본문에 사용하는 방식으로 한정된다.
- 인라인 함수의 본문에서 람다 식을 바로 호출하거나 람다 식을 인자로 전달받아 호출하는 경우, 인라이닝 할 수 없다.
- 그 외에는 컴파일러가 인라이닝을 금지시킨다.
- 인라이닝은 어쨌든 string 대치를 컴파일러에서 하는 것이고, 대치하려고 호출했는데 계속 타고 들어가는 경우 재귀호추로 인한 문제가 생길 수 있어 금지 시킨다.
- 어떤 람다에 너무 많은 코드가 들어가거나 어떤 람다에 인라이닝을 하면 안되는 코드가 들어갈 가능성이 있다면 인라이닝을 하면 안된다.
noinline변경자를 파라미터 앞에 붙여 인라이닝을 금지할 수 있다.- 코틀린에서는 어떤 모듈이나 서드파티 라이브러리 안에서 인라인 함수를 정의하고 그 모듈이나 라이브러리 밖에서 해당 인라인 함수를 사용할 수 있다.
- 자바에서도 코틀린에서 정의한 인라인 함수를 호출할 수 있다.
- 이런 경우, 인라인 함수를 인라이닝 하지 않고 일반 함수 호출로 컴파일 한다.
컬렉션 연산 인라이닝
- 시퀀스는 람다를 인라인 하지 않기 때문에 모든 컬렉션 연산에
asSequence를 붙여서는 안된다. - 람다가 인라이닝 되지 않기 떄문에 크기가 작은 컬렉션은 오히려 성능이 안좋아진다.
- 시퀀스를 통해 성능 향상 시킬 수 있는 경우는 크기가 큰 경우 뿐이다.
함수를 인라인으로 선언해야 하는 경우
- 람다를 인자로 받는 함수만 성능이 좋아질 가능성이 높다.
- 람다를 인자로 받는 함수를 인라이닝 하면 장점
- 인라이닝을 통해 없앨 수 있는 부가 비용이 크다.
- 현재 JVM은 함수 호출과 람다를 인라이닝 해줄 정도로 똑똑하지 못하다.
- 일반 람다에서 사용할 수 없는 넌로컬 반환 등의 기능을 사용할 수 있다.
- 인라이닝 시 주의할 점은 함수가 큰 경우에는 본문에 해당 하는 바이트코드를 모든 호출지점에 복사해 넣고 나면 바이트코드가 전체적으로 아주 커질 수 있다.
자원 관리를 위해 인라인 된 람다 사용
- 람다로 중복을 없애는 대표적인 케이스는 자원관리이다.
- try/finally 문을 사용하되 try 시작 전에 자원 획득, finally에서 자원 해제하는 방식
- 자바에서는 try-with-resource 사용, 코틀린에서는
use함수를 사용한다.use는 닫을 수 있는 자원에 대한 확장 함수이며 람다를 인자로 받는다.- 람다 본문 안의 return은 넌로컬 return, 함수를 끝내면서 값을 반환한다.
고차 함수 안에서 흐름제어
람다 안의 return문 : 람다를 둘러싼 함수로부터 반환
- 람다 안에서 return을 사용하면 람다로부터만 반환되는 게 아니라 그 람다를 호출하는 함수가 실행을 끝내고 반환된다.
- 자신을 둘러싸고 있는 블록보다 더 바깥에 있는 다른 블록을 반환하게 만드는 return문을
non-local return이라 부른다. (람다를 인자로 받는 함수가 인라인인 경우에만 가능) - 인라이닝 되지 않은 함수에 전달되는 람다 안에서 return을 사용할 수 없다.
람다로부터 반환: 레이블을 사용한 return
- 람다 식에서의 로컬 리턴을 사용(for의 break 와 비슷)할 수 있다.
로컬 리턴과 넌로컬 리턴을 구분하기 위해
label을 사용한다.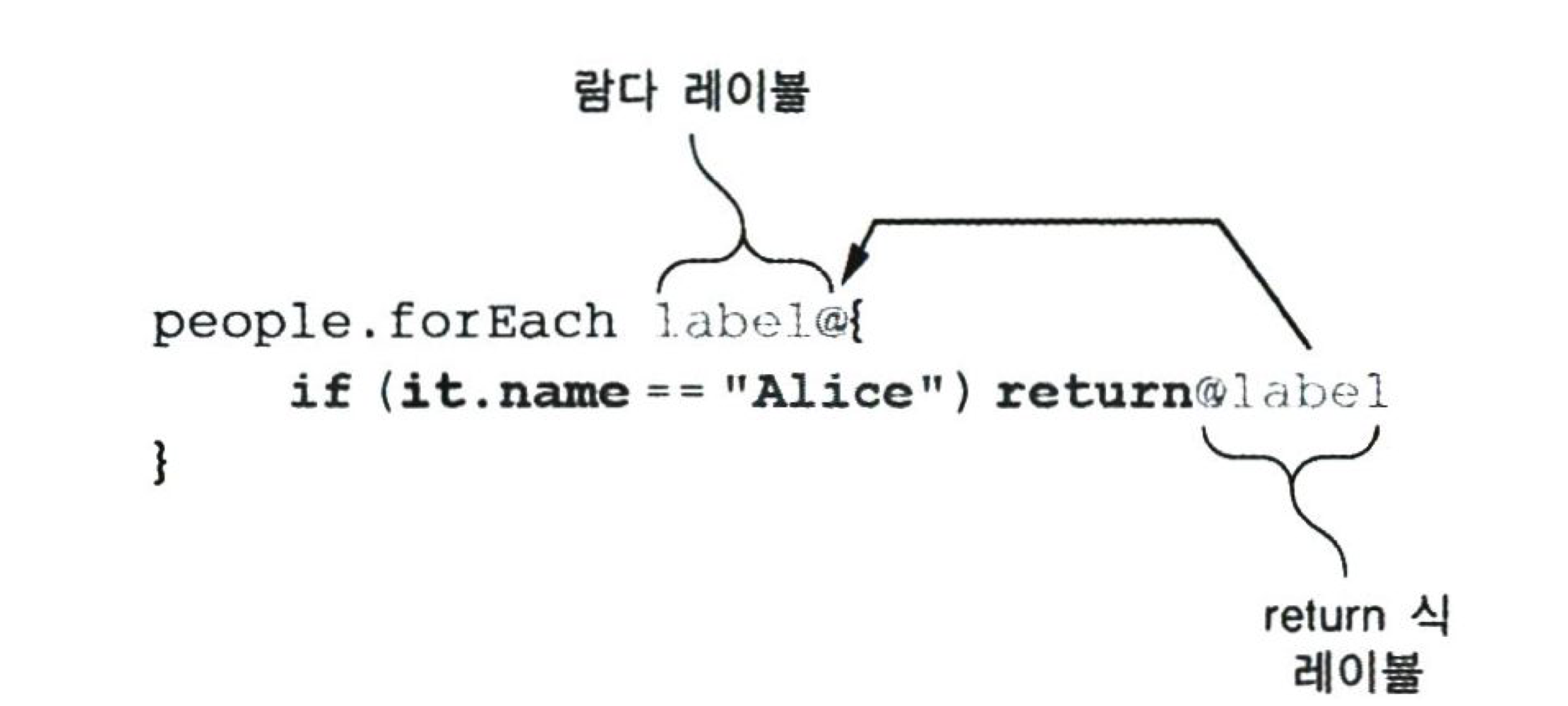
인라인 함수의 이름을 return 뒤에 레이블로 사용해도 된다.
fun lookForAlice(people: List<Person>) { people.forEach { if (it.name == "Alice") return@forEach } } ...- 레이블을 명시하면 함수이름을 레이블로 사용할 수 없고, 레이블이 2개 이상 붙을 수 없다.
수신 객체 지정 람다 앞에 레이블을 붙인 경우,
this뒤에 그 레이블을 붙여 묵시적인 컨택스트 객체를 지정할 수 있다.println(StringBuilder().apply sb@ { listOf(1,2,3).apply { this@sb.append(this.toString()) } })
무명 함수: 기본적으로 로컬 return
- 레이블이 붙지 않은
return식은 무명함수 자체를 반환한다. return은fun키워드를 사용해 정의되 가장 안쪽 함수를 반환한다.
9장. 제네릭스
- 선언 지점 변성 : 실체화한 타입 파라미터를 사용하면 구체적인 타입을 실행 시점에 알 수 있다.
- 사용 지점 변성 : 같은 목표(제네릭 타입 값 사이의 상/하위 타입 관계 지정)를 제네릭 타입 값을 사용하는 위치에서 파라미터 타입에 대한 제약을 표시.
제네릭 타입 파라미터
- 어떤 타입의 파라미터를 받을 것인가? 에 대한 내용.
// 기본 골조
val authors: List<String> = listOf("Dmitry", "Svetlana")
// 여기서는 listOf 의 인자로 String이 왔기 때문에 컴파일러는 타입 추론이 가능하여 생략이 가능하다.
val authors = listOf("Dmitry", "Svetlana")
// 빈 리스트를 만들어야 하기 때문에 컴파일러가 타입을 추론할 수 없다. 타입을 명시해야 한다.
val readers: MutableList<String> = mutableListOf()
// 이런 식으로 선언하는 쪽에서 타입을 지정해도 가능하다.
val readers = mutableListOf<String>()
- 자바는 빈 타입이 올 수 있지만, 코틀린에서는 항상 타입 선언을 명시적으로 해주어 컴파일러가 인지할 수 있도록 해주어야 한다.
- 프로그래머가 명시하거나 컴파일러가 추론 가능케 해야 한다.
제네릭 함수와 프로퍼티

- 함수 선언 앞에 타입 파라미터를 선언하여, 함수의 파라미터 혹은 반환 값에서 사용할 수 있다.
- 타입 인자를 명시적으로 지정할 수 있다. 하지만 컴파일러가 보통 추론이 가능해 명시하지 않아도 된다.
fun main() {
val authors = listOf("Dmitry", "Svetlana")
val readers = mutableListOf<String>(/**/)
fun <T> List<T>.filter(predicate: (T) -> Boolean): List<T>
// List<T> -> readers -> mutableListOf<String>
readers.filter { it !in authors } // 여기서 호출하는 함수로 인해 T가 String임을 추론한다.
}
- 제네릭 확장 프로퍼티를 선언할 수 있다. 다만, 확장 프로퍼티만 제네릭하게 만들 수 있다. 일반 프로퍼티는 불가능 하다.
- 코틀린에서는 클래스 수준에서만 제네릭 타입을 선언할 수 있으며, 프로퍼티 수준에서는 직접적으로 타입 매개변수를 사용할 수 없습니다. 하지만 제네릭 타입을 클래스 수준에서 정의하고 해당 타입을 프로퍼티에서 사용할 수 있습니다.
class Box<T>(val value: T)
// Type parameter of a property must be used in its receiver type
// 변수 자체를 제네릭 하게 바로 사용할 수 없음.
val <T> box:T = TODO() // compile error
// 이와 같이 확장 프로퍼티로 사용해야 사용이 가능함.
fun <T> Box<T>.printValue() {
val x: T = this.value
println(x)
}
제네릭 클래스 선언
- 타입 파라미터를 넣은 꺽쇠 기호를 클래스(인터페이스) 이름 뒤에 붙여 제네릭하게 만든다.
- 제네릭 클래스를 확장하는 클래스를 정의하려면 기반 타입의 제네릭 파라미터에 대해 인자를 지정해야 한다.
- 클래스가 자기 자신을 타입 인자로 참조할 수 있다.
interface List<T> {
operator fun get(index: Int): T
}
class ArrayList<X> : List<X> { // 기반 타입의 제네릭 파라미터에 대해 인자 X를 지정. List의 제네릭 파라미터 타입 인자로 넘긴다.
override fun get(index: Int): X {
TODO()
}
}
// in Java
interface test<T> {
T get(T param);
}
class extendTest implements test<String> {
@Override
public String get(String param) {
return param;
}
}
class extendTest2<X> implements test<X> {
@Override
public X get(X param) {
return param;
}
}
타입 파라미터 제약
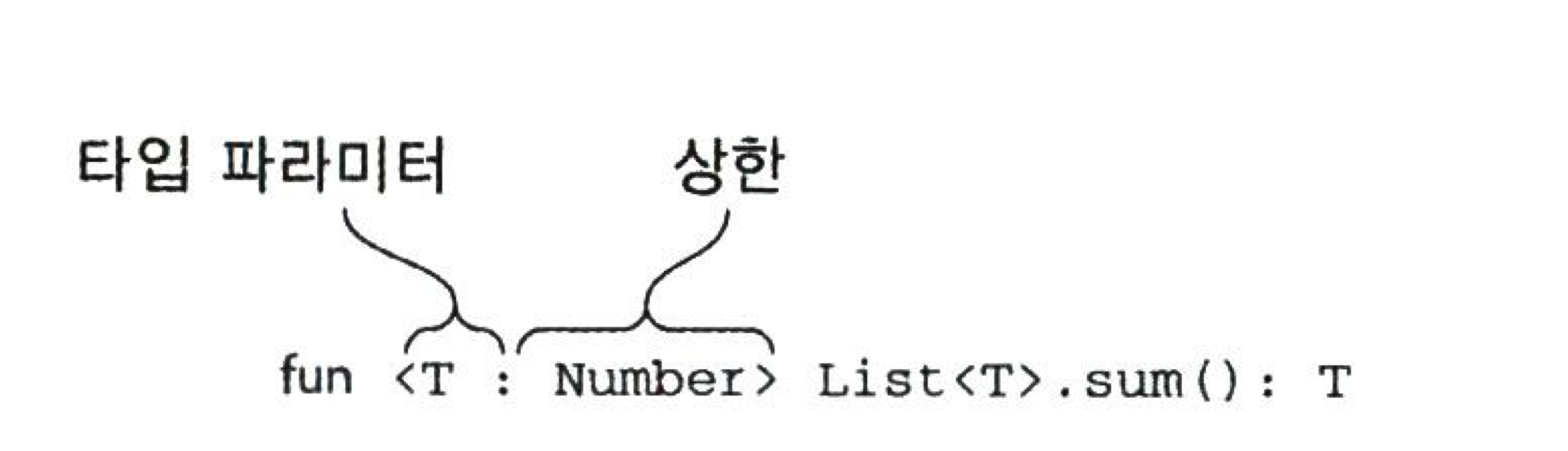
- 클래스나 함수에 사용할 수 있는 타입 인자를 제한하는 기능.
- 어떤 타입을 제네릭 타입의 타입 파라미터 상한으로 지정하면 그 제네릭 타입을 인스턴스화 할 때는 그 타입이거나 하위 타입이어야 한다.
fun <T : Comparable<T>> max(first: T, second: T): T {
// 이 함수의 인자들은 비교가능해야 한다.
return if (first > second) first else second
}
fun main() {
// 문자열을 알파벳순으로 비교한다.
println(max("kotlin", "java"))
// Kotlin: Type mismatch: inferred type is String but IntegerLiteralType[Int,Long,Byte,Short] was expected
// 비교할 수 없는 타입에서는 컴파일 오류가 발생한다.
// String 타입도 아니고, String의 하위 타입도 아니기 때문에.
// println(max("kotlin", 42))
}
- 타입 파라미터에 대해 2개 이상의 제약을 가해야 하는 경우.
fun <T> ensureTrailingPeriod(seq: T)
// 타입 파라미터 제약 목록이다.
where T : CharSequence, T : Appendable {
// CharSequence 인터페이스의 확장 함수를 호출 한다.
if (!seq.endsWith('.')) {
// Appendable 인터페이스의 메서드를 호출 한다.
seq.append('.')
}
}
타입 파라미터를 널이 될 수 없는 타입으로 한정
- 널이 될 수 있는 타입을 포함하는 어떤 타입으로 타입 인자를 지정해도 타입 파라미터를 치환할 수 있다.
Any?를 상한으로 정한 파라미터와 같다.- 널이 될 수 없는 타입만 타입 인자를 받으려면
Any?대신Any를 상한으로 사용한다.
실행 시 제네릭스의 동작: 소거된 타입 파라미터와 실제화된 타입 파라미터
- 타입 소거 : 실행 시점에 제네릭 클래스의 인스턴스에 타입 인자 정보가 들어있지 않다.
- 함수를 인라인으로 만들면 타입 인자가 지워지지 않게 할 수 있다.
fun main() {
val value = listOf(1,2,3)
when(value){
// Cannot check for instance of erased type: List<String> 에러 발생.
// 타입을 체크할 수 없다!
is List<String> -> println("String List")
is List<Int> -> println("Int List")
}
}
실행 시점의 제네릭: 타입 검사와 캐스트
- Type Check
- 코틀린 제네릭 타입 인자 정보는 런타임에 지워진다.
- 실행 시점에 타입 인자를 검사할 수 없다.
is검사에서 타입 인자로 지정한 타입을 검사할 수는 없다. - 저장해야하는 타입 정보의 크기가 줄어 메모리 사용량이 줄긴 한다(장점)
스타 프로젝션(star projection)을 사용하여 타입 인자를 명시한다.
// 나도 몰라. 니가 실행 시점에 알아서 판단해. if ( value is List<*>) { ... }- 타입 파라미터가 2개 이상이라면 모든 타입 파라미터에
*를 포함 시켜야 한다. - 인자를 알 수 없는 제네릭 타입을 표현할 때, 스타 프로젝션을 사용한다.
- Cast
- 타입 인자가 다른 타입으로 캐스팅 해도 여전히 캐스팅에 성공한다는 사실을 조심해야 한다.
- 실행 시점에는 인자를 알 수 없어 캐스팅은 항상 성공한다.
// 스타 프로젝션을 포함하여 아래에서 형변환을 하더라도, 문제는 없으나 // 정확하지 않기 때문에 타입 캐스팅 경고를 알려준다. fun printSum2(c: Collection<*>){ val intList = c as? List<Int> // Unchecked cast: Collection<*> to List<Int> 캐스팅 경고가 발생한다. ?: throw IllegalArgumentException("List is expected") println(intList.sum()) } // 실행은 성공한다. fun main() { printSum2(listOf(1,2,3,4)) } - 코틀린 컴파일러는 컴파일 시점에 타입 정보가 주어진 경우에는 is 검사를 수행하게 허용할 수 있을 정도로 똑똑하다.
- 타입 인자가 다른 타입으로 캐스팅 해도 여전히 캐스팅에 성공한다는 사실을 조심해야 한다.
- 코틀린은 제네릭 함수의 본문에서 그 함수의 타입 인자를 가리킬 수 있는 특별한 기능을 제공하지 않는다. 하지만, inline 함수 안에서는 타입 인자를 사용할 수 있다.
실체화한 타입 파라미터를 사용한 함수 선언
- 제네릭 함수가 호출되도 그 함수의 본문에서는 호출 시 쓰인 타입 인자를 알 수 없다.
- 인라인 함수의 타입 파라미터는 실체화되므로 실행 시점에 인라인 함수의 타입 인자를 알 수 있다.
- 인라인 함수로 만들면, 코드도 함께 인라이닝 되고, 그에 따라 무명 클래스와 객체가 생성되지 않아 성능이 좋아질 수 있다.
- 인라인 함수는 함수 타입이 있고, 그 인자를 함께 인라이닝 하여 얻는 이익이 큰 경우에만 인라인 함수로 만들라고 했다.
- 하지만, 성능 향상의 목적이 아닌 실체화한 타입 파라미터를 사용하기 위한 것은 괜찮다.
// 함수를 인라인으로 선언하고 타입 파라미터에 reified 키워드를 지정한다.
// 그러면 밑에서 element가 T 인지 실행시점에 검사 할 수 있다.
inline fun <reified T> Iterable<*>.filterIsInstance(): List<T>{
val destination = mutableListOf<T>()
for (element in this){
// reified 키워드가 붙은 타입이라 실행 시점에 검사 하라는 의미. (인라인 에서만 사용 가능)
if (element is T) destination.add(element)
}
return destination
}
실체화한 타입 파라미터로 클래스 참조 대신
- 실체화한 타입 파라미터를 활용해 클래스 참조 대신 사용한다.
// 클래스를 얻는 스프링/안드로이드 서비스 로더 예시 정의
inline fun <reified T> loadService() {
return ServiceLoader.load(T::class.java)
}
// 아래의 2개는 동일항 코드 이지만, 윗 코드에 클래스 자체 타입을 인자로 줌으로써 좀 더 빠르고 명확하게 타입 인자를 알 수 있다.
val serviceImpl = ServiceLoader.load(Service::class.java)
val serviceImpl = ServiceLoader<Service>
실체화한 타입 파라미터의 제약
- 실체화한 타입 파라미터를 사용 가능한 경우
- 타입 검사와 캐스팅(
is,!is,as,as?) - 코틀린 리플렉션 API(
::class) - 코틀린 타입에 대응하는
java.lang.Class를 얻기(::class.java) - 다른 함수를 호출할 때 타입 인자로 사용
- 타입 검사와 캐스팅(
- 불가능한 기능 영역
- 타입 파라미터 클래스의 인스턴스 생성
- 타입 파라미터 클래스의 동반 객체 메서드 호출
- 실체화 한 파라미터를 요구하는 함수를 호출하면서 실체화 하지 않은 타입 파라미터로 받은 타입을 타입 인자로 넘기기
- 클래스, 프로퍼티, 인라인 함수가 아닌 함수의 타입 파라미터를
reified로 지정하기.
변성: 제네릭과 하위 타입
A 타입이 B 타입의 하위 타입이라고 해서, 해당 타입을 파라미터로 받는 컬렉션 사이에서 타입 관계가 적용되지 않을 때. 둘 사이의 관계를 정의하는 것.
변성이 있는 이유: 인자를 함수에 넘기기
- 인자를 함수에 넘길때 타입 간의 관계를 모르는 상황에서 문제가 발생할 수 있다.
List<Any>타입의 파라미터를 받는 함수에List<String>을 넘기면 안전한가?- 변경이 있다면 안전하지 않다. → 파라미터 받는 쪽에서 이상한 작업을 하게되면? → 에러 발생
- 변경이 없다면 안전한 상태다. → 변경이 없다면 오류가 발생활 확률이 없다.
- 특정 관계(하위타입과 상위타입)를 갖는 파라미터를 인자로 넘기는 위와 같은 상황을 모든 제네릭 클래스에 적용할 수 있다.
클래스, 타입, 하위 타입
- 클래스
- 모든 코틀린 클래스는 적어도 둘 이상의 타입을 구성할 수 있다.
- 제네릭 클래스
- 타입 파라미터를 구체적인 타입 인자로 바꾸어 주어야 한다.
하위 타입
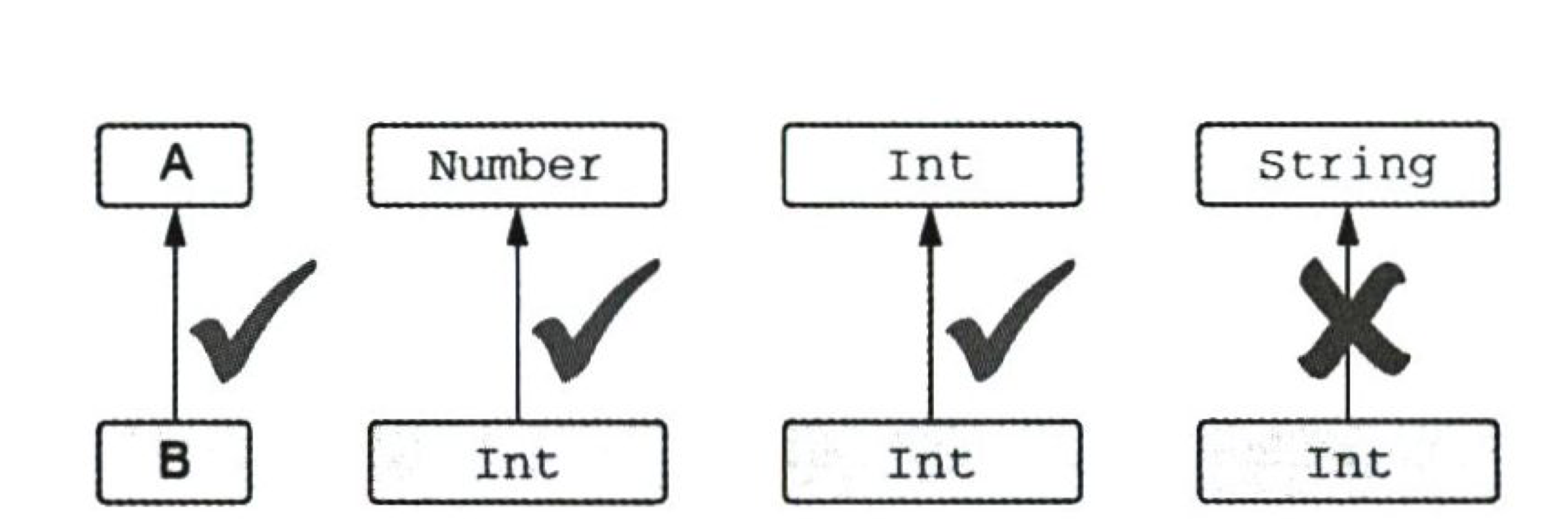
- A 타입의 값이 필요한 모든 장소에 B 타입을 넣어도 문제가 없다면 B는 A의 하위 타입이다.
- 상위 타입
- 하위 타입의 반대 케이스이다.
- 컴파일러는 변수 대입이나 함수 인자 전달 시, 하위 타입 검사를 매번 실시 한다.
선언 지점 변성 : 클래스를 선언하면서 클래스 자체에 변성을 지정하는 방식
- (클래스에 in/out을 지정하는 방식)
| 종류 | 의미 | 사용 위치 | 예시 |
|---|---|---|---|
| 공변성(covariant) | T1가 T의 서브타입이면, C | T를 아웃 위치에서만 사용할 수 있다. (반환 값이나, 인스턴스 함수 인자) | fun test(param: List |
| 반공변성(contravariant) | T1가 T의 서브타입이면, C | T를 인 위치에서만 사용할 수 있다.(파라미터 타입) | fun test(param: List |
| 무공변성(invariant) | C와 C | T를 아무 위치에서나 사용할 수 있다. | fun test(param: List |
공변성 : 하위 타입 관계를 유지
공변성을 표시하려면 타입 파라미터 이름 앞에
out을 붙인다.interface Producer<out T> { ... }- 타입이 정확히 일치하지 않아도 클래스 인스턴스를 함수 인자나 반환 값으로 사용할 수 있다.
- 클래스가 T 타입의 값을 생산할 수는 있지만 소비할 수 없다. (T 타입의 값을 반환할 수는 있지만, 파라미터 타입으로는 쓸 수 없다.)
- 위험할 여지가 있는 메서드를 호출 할 수 없게 함으로써 제네릭 타입의 안정성을 확보한다.
- 외부에서 볼 수 있는(public, protected, internal) 클래스에만 적용 가능하다.
class Box<Out T>(val size : Int) // 공변성으로 제네릭 클래스 선언
fun main() {
val anys : Box<Any> = Box<Int>(10) // Int는 Any의 하위 클래스이므로 객체 생성 가능
val nothings : Box<Nothing> = Box<Int>(10) // 오류, 자료형 불일치
}
// Any의 경우 Int의 상위 클래스이므로 Int형으로 생성한 객체도 Any에 포함할 수 있다.
// 하지만 Nothing의 경우 Int의 하위 클래스이므로 Int형으로 생성한 객체를 포함할 수 없다
반공변성 : 뒤집힌 하위 타입 관계
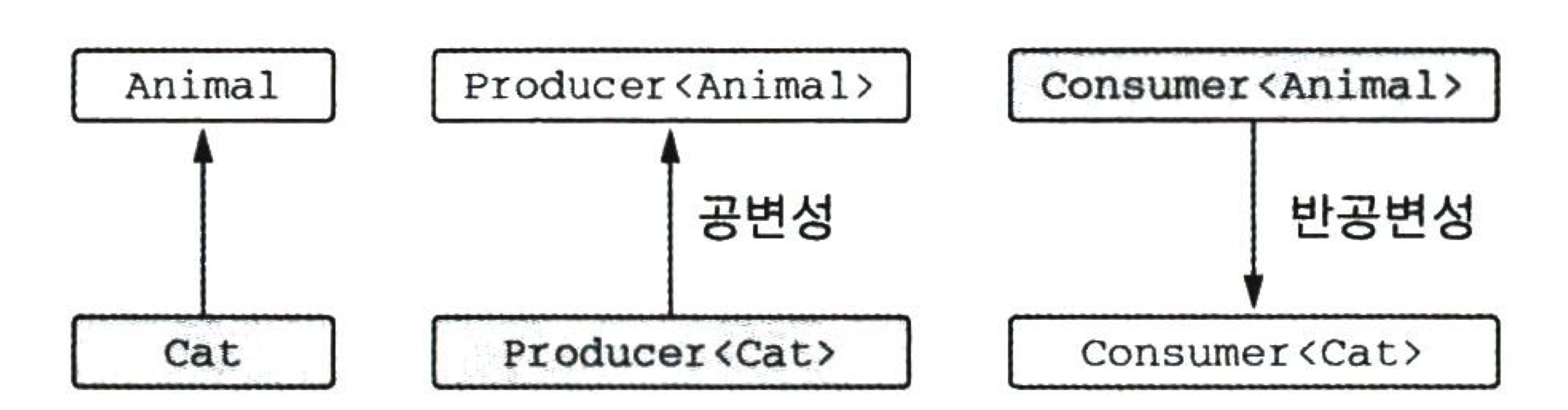
반공변성을 표시하려면 타입 파라미터 이름 앞에
in을 붙인다.interface Comparator<in T> { fun compare(e1: T, e2: T): Int { ... } }- 파라미터 타입으로 사용할 수 있다.
class Box<in T>(val size : Int) // 반공변으로 선언
// Any -> Int -> Nothing
fun main() {
val anys: Box<Any> = Box<Nothing>(10) // 오류, 자료형 불일치. 여기서는 Any와 Any의 부모 타입만 받을 수 있는데 하위 타입이 왔다.
val nothings: Box<Nothing> = Box<Int>(10) // 자기 자신(Nothing)과 부모 타입(Int)만 받으므로 선언이 가능하다.
}
무변성 : 관계가 없다. 정확하게 일치해야 한다.
class Box<T>(val size : Int) // 무변성으로 제네릭 클래스 선언
fun main() {
val anys : Box<Any> = Box<Int>(10) // 오류, 자료형 불일치
val nothings : Box<Nothing> = Box<Int>(10) // 오류, 자료형 불일치
}
사용 지점 변성 : 타입이 언급되는 지점에서 변성 지정
- 선언 지점 변성 : 클래스를 선언하면서 변성을 지정한다.
- 사용 지점 변성 : 타입 파라미터가 있는 타입을 사용할 때마다 명시한다.
- 타입 프로젝션(Type Projection) : 타입 파라미터가 있는 타입을 사용할 때마다 해당 타입 파라미터를 하위 타입이나 상위 타입 중 어떤 타입으로 대치할 수 있는지를 명시해야 한다.
- 파라미터 타입, 로컬 변수 타입, 함수 반환 타입 등에 타입 파라미터가 쓰이는 경우
in이나out변경자를 붙일 수 있다.
- 파라미터 타입, 로컬 변수 타입, 함수 반환 타입 등에 타입 파라미터가 쓰이는 경우
스타 프로젝션 : 타입 인자 대신 * 를 사용
- 해당 타입을 정확히 모른다는 것을 표현한다.
- 아무거나 담아도 된다는 것은 아니고, 제네릭 타입 파라미터가 어떤 타입인지 굳이 알 필요가 없을 때만 사용할 수 있다.
- 아무거나 담으면 안된다?
*타입과Any?타입은 다른 의미이다.*타입으로 받고 나서 타입이 결정되는 지점이 존재하고, 타입이 결정되면 해당 타입과 그에 대한 하위 타입만 받을 수 있기 때문이다.
- 이러한 패턴을 모든 커스텀 제네릭 클래스를 저장할 때 사용할 수 있도록 확장이 가능하다.
- 결국 목적은, 안전하지 못한 코드를 별도로 분리하여 잘못 사용하지 않도록 하고 안전하게 사용하기 위함이다.
10장. 애노테이션과 리플렉션
애노테이션 선언과 적용
애노테이션 적용
애노테이션을 지정하는 문법
- 클래스를 애노테이션 인자로 지정할 때는
@MyAnnotation(MyClass::class)처럼::class를 클래스 이름 뒤에 넣는다. - 다른 애노테이션을 인자로 지정할 때는 인자로 들어가는 애노테이션의 이름앞에
@를 넣지 않는다. - 배열을 인자로 지정하려면
@RequestMapping(path = arrayOf("/foo","/bar"))처럼 생성 전용 함수를 사용한다. - 자바에서 선언한 애노테이션을 사용한다면
value라는 이름의 파라미터가 필요에따라 자동으로 가변 길이 인자로 변환된다. 그런 경우에는@JavaAnnotationWithArrayValue("abc","foo","bar")처럼 생성 전용 함수를 사용하지 않는다.
애노테이션 인자를 컴파일 시점에 알 수 있어야 한다.
- 임의의 프로퍼티를 인자로 지정할 수 없는데, 프로퍼티를 인자로 사용하려면
const변경자를 붙인다.
애노테이션 대상
- 사용 지점 대상(use-site target) 선언으로 애노테이션을 붙일 요소를 정할 수 있다.
지점 대상은
@기호와 애노테이션 이름 사이에 붙으며, 애노테이션 이름과는 콜론으로 분리된다.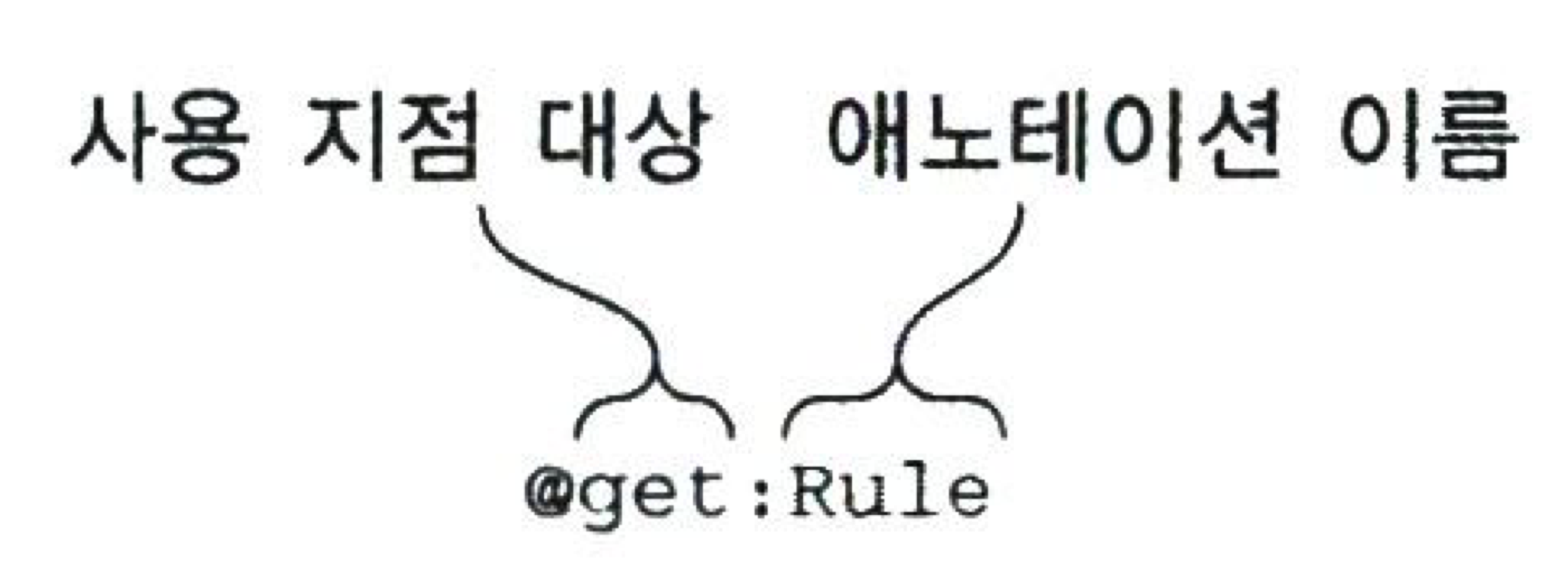
- 코틀린으로 애노테이션을 선언하면 프로퍼티에 직접 적용할 수 있는 애노테이션을 만들 수 있다.
- 지원 대상 목록
propertyfieldgetsetreceiverparamsetparamdelegatefile
- 자바와 달리 코틀린에서는 애노테이션 인자로 클래스나 함수 선언, 타입 외에 임의의 식을 허용한다.
fun test(list: List<*>) {
@Suppress("UNCHECKED_CAST")
val strings = list as List<String>
...
}
애노테이션을 활용한 JSON 직렬화 제어
- 생략
애노테이션 선언
annotation class JsonExclude
- 애노테이션 클래스는 메타데이터의 구조를 정의하기 때문에, 내부에 아무 코드가 없어야 한다.
- 컴파일러는 애노테이션 클래스에서 본문을 정의하지 못하게 막는다.
- 파라미터가 있는 애노테이션을 정의하려면 클래스의 주 생성자에 파라미터를 선언해야 한다.
annotation class JsonName(val name: String)
- 일반 클래스의 주 생성자 선언 구문을 똑같이 사용한다.
- 단, 애노테이션 클래스에서는 모든 파라미터 앞에
val을 붙여야 한다. - 자바에서 선언한 애노테이션을 코틀린의 구성 요소로 적용할 때는
value를 제외한 모든 인자에 대해 이름을 붙인 인자 구문을 사용한다.
메타애노테이션: 애노테이션을 처리하는 방법 제어
- 애노테이션 클래스에 적용할 수 있는 애노테이션을 메타애노테이션이라고 한다.
- 컴파일러가 애노테이션을 처리하는 방법을 제어한다.
@Target과 같이 의존관계 주입 라이브러리들이 메타애노테이션을 사용해 주입 가능한 타입이 동일한 여러 객체를 식별한다.- 타겟 애노테이션은 애노테이션을 적용할 수 있는 요소의 유형을 정의한다.
- 타겟을 지정하지 않으면 모든 선언에 적용할 수 있다.
애노테이션 파라미터로 클래스 사용
- 클래스 참조를 파라미터로 하는 애노테이션 클래스를 선언하면 기능을 사용할 수 있다.
interface Company {
val name: String
}
data class CompanyImpl(override val name: String) : Company
data class Person (
val name: String,
// 파라미터로 클래스를 받았다. JSON을 역직렬화 하면서 CompanyImpl 인스턴스를 만들어
// Person 인스턴스의 company 프로퍼티에 설정하도록 한다.
@DeserializeInterface(CompanyImpl::class) val company: Company
}
애노테이션 파라미터로 제네릭 클래스 받기
- 타입 인자를 제공해야 한다.
애노테이션이 어떤 타입에 쓰일지 모르므로 스타 프로젝션을 사용할 수 있다.

interface ValueSerializer<T> {
fun toJsonValue(value: T): Any?
fun fromJsonValue(jsonValue: Any?): T
}
annotation class CustomSerializer(
val serializerClass: KClass<out ValueSerializer<*>>
}
data class Person(
val name: String,
@CustomSerializer(DataSerializer::class) val birthDate: Date
}
- 클래스로 인자를 받아야 하면 애노테이션 파라미터 타입에
KClass<out 허용할클래스이름>을 사용한다. - 제네릭 클래스를 인자로 받아야 하면
KClass<out 허용할클래스이름<*>>처럼 스타 프로젝션을 붙여 사용한다.
리플렉션 : 실행 시점에 코틀린 객체 내부 관찰
실행 시점에 (동적으로) 객체의 프로퍼티와 메서드에 접근할 수 있게 해주는 방법. 즉, 프로그램이 실행중일 때 인스턴스 등을 통해 객체의 내부 구조 등을 파악할 수 있습니다.
코틀린에서 리플렉션을 사용하기 위해 다뤄야 하는 API
java.lang.reflect패키지를 통해 제공하는 표준 리플렉션- 코틀린이
kotlin.reflect패키지를 통해 제공하는 코틀린 리플렉션 API
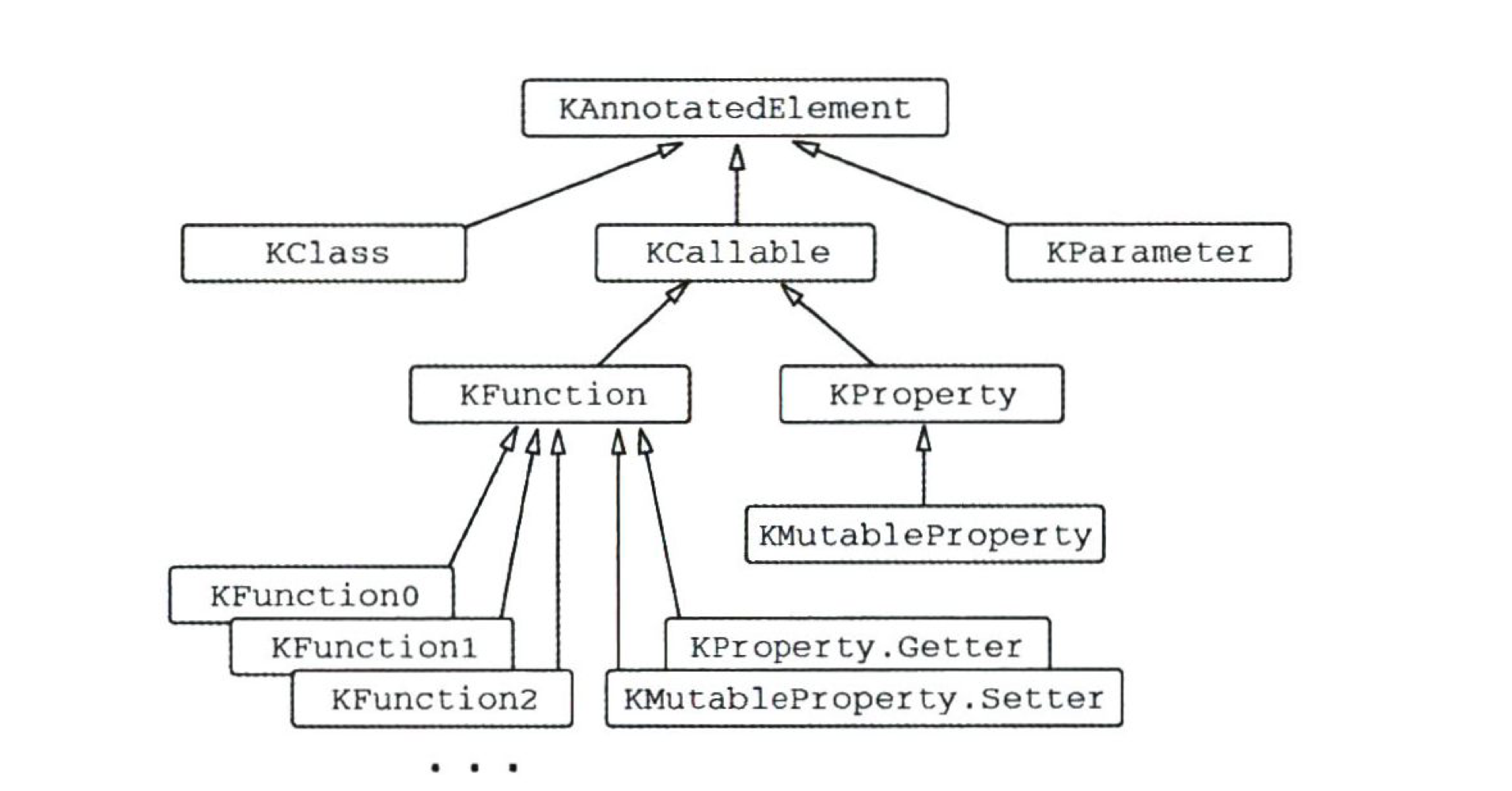
코틀린 리플렉션 API : KClass, KCallable, KFunction, KProperty
- KClass
- 클래스를 표현하는 리플렉션
MyClass::class라는 식으로 인스턴스를 얻는다.java.lang.Object.getClass()와 같다.
- KCallable
- 함수와 프로퍼티를 아우르는 공통 상위 인터페이스
call메서드를 통해 함수나 프로퍼티의 게터를 호출할 수 있다.call에 넘긴 인자 개수와 원래 함수에 정의된 파라미터 개수가 맞아야 한다.
- KFunction
- 함수를 호출하기 위한 구체적인 메소드
KFunction1<Int,Unit>을 예로 들자면, 1은 함수의 파라미터가 1개라는 의미이다.- KFunction 인터페이스를 통해 함수를 호출하려면
invoke메소드를 사용해야 한다.- 정해진 개수의 인자만 받는다.
- 인자 타입과 반환 타입을 모두 다 알면
invoke를 호출하는게 낫다. call메서드는 모든 타입의 함수에 적용 가능하지만, 타입 안정성을 보장하지 않는다.
코틀린에서는 컴파일러가 생성한 합성 타입을 사용하기 때문에 원하는 수만큼 많은 파라미터를 갖는 함수에 대한 인터페이스를 사용할 수 있다. 이를 통해 런타임.jar 크기를 줄이거나 파라미터 개수에 의한 제약을 회피한다.
예를 들면, KFunction2<P1,P2,R> 에는 operator fun invoke(p1: P1, p2: P2): R 선언이 들어있다.
</aside>
- KProperty
- KProperty의
call은 프로퍼티의 getter() 를 호출한다. - 멤버 프로퍼티는 KProperty1 인스턴스로 표현된다.
- 제네릭 클래스다.
- 수신 객체를 넘길때는 타입 파라미터와 일치하는 타입의 객체만 넘길 수 있다.
memberProperty.get("alice")와 같은 호출은 컴파일 되지 않는다.- 최상위 수준이나 클래스 안에 정의된 프로퍼티만 리플렉션으로 접근할 수 있고 함수의 로컬 변수에는 접근할 수 없다.
- KProperty의
- 코틀린 리플렉션 API의 인터페이스 계층 구조
리플렉션을 사용한 객체 직렬화 구조
private fun StringBuilder.serializeObject(obj: Any) {
val kClass = obj.javaClass.kotlin // 객체의 kclass를 얻는다.
val properties = kClass.memberProperties // 클래스의 모든 프로퍼티를 얻는다.
properties.joinToStringBuilder(
this, prefix = "{", postfix = "}"
) { prop ->
serializeString(prop.name) // 프로퍼티의 이름을 얻는다.
append(": ")
serializePropertyValue(prop.get(obj)) // 프로퍼티의 값을 얻는다.
}
}
- 수신 객체 타입을 컴파일 시점에 검사하지 못하나, 프로퍼티의 get에 넘기는 객체가 바로 그 프로퍼티를 얻어온 객체(obj)이기 때문에 항상 프로퍼티 값이 제대로 반환된다.
애노테이션을 활용한 직렬화 제어
- 특정 어노테이션이 붙은 프로퍼티를 제외하기
val jsonNameAnn = prop.findAnnotation<JsonName>() // @JsonName 애노테이션이 있으면 그 인스턴스를 얻는다.
val propName = jsonNameAnn?.name ?: prop.name // 애노테이션에서 name을 찾고, 없으면 prop.name 을 사용한다.
- 프로퍼티의 값을 직렬화 하는 직렬화 객체 가져오기
fun KProperty<*>.getSerializer(): ValueSerializer<Any?>? {
val customSerializerAnn = findAnnotation<CustomSerializer>() ?: return null
val serializerClass = customSerializerAnn.serializerClass
val valueSerializer = serializerClass.objectInstance // object 선언에 의해 생성된 싱글턴을 가리킴.
?: serializerClass.createInstance()
@Suppress("UNCHECKED_CAST")
return valueSerializer as ValueSerializer<Any?>
}
- 코틀린 싱글턴 객체에는 생성된 싱글턴을 가리키는
objectInstance라는 프로퍼티가 있다. - 싱글턴 인스턴스가 있어 이를 이용해 모든 객체를 직렬화 할 수 있으므로
createInstance()를 호출할 필요가 없다. - 하지만, KClass가 일반 클래스를 표현한다면
createInstance()를 호출해서 새 인스턴스를 만들어야 한다.
JSON 파싱과 객체 역직렬화
class ObjectSeed<out T: Any> (
targetClass: KClass<T>,
val classInfoCache: ClassInfoCache
): Seed {
// targetClass의 인스턴스를 만들 때 필요한 정보를 캐싱한다.
private val classInfo: ClassInfo<T> =
classInfoCache[targetClass]
private val valueArguments = mutableMapOf<KParameter, Any?>()
private val seedArguments = mutableMapOf<KParameter, Seed>()
private val arguments: Map<KParameter, Any?> // 생성자 파라미터와 그 값을 연결하는 맵을 만든다.
get() = valueArguments +
seedArguments.mapValues { it.value.spawn() }
override fun setSimpleProperty(propertyName: String, value: Any?) {
val param = classInfo.getConstructorPrarmeter(propertyName)
valueArguments[param] = // 널 생성자 파라미터 값이 간단한 값인 경우 그 값을 기록한다.
classInfo.deserializeConstructorArgument(param, value)
}
override fun createCompositeProperty(propertyName: String, isList: Boolean): Seed {
val param = classInfo.getConstructorParameter(propertyName)
val deserializeAs = // 프로퍼티에 대한 애노테이션이 있다면 그 값을 가져온다.
classInfo.getDeserializeClass(propertyName)
val seed = createSeedForType( // 파라미터 타입에 따라 ObjectSeed나 CollectionSeed를 만든다.
deserializeAs ?: param.type.javaType, isList
)
// 만든 시드 객체를 seedArguments 맵에 기록한다.
return seed.apply { seedArguments[param] = this}
}
// 인자 맵을 넘겨서 targetClass 타입의 인스턴스를 만든다.
override fun spawn(): T =
classInfo.createInstance(arguments)
}
최종 역직렬화 단계 : callBy(), 리플렉션을 사용해 객체 만들기
[KCallable.call](http://KCallable.call)은 인자 리스트를 받아서 함수나 생성자를 호출해준다.- 디폴트 파라미터를 지원하지 않는 한계가 있다.
KCallable.callBy는 디폴트 파라미터를 지원한다.interface KCallable<out R> { fun callBy(args: Map<KParameter, Any?>): R ... }- 파라미터와 파라미터에 해당하는 값을 연결해주는 맵을 인자로 받는다.
- 파라미터의 순서를 지킬 필요가 없다.
- 이름과 일치하는 파라미터를 찾은 후, 맵에 파라미터 정보와 값을 넣을 수 있다.
ClassInfoCache는 리플렉션의 연산 비용을 줄이기 위한 클래스.- 객체를 역직렬화 할 때는 프로퍼티가 아니라 생성자 파라미터를 다룬다.
class ClassInfoCache {
// 캐시에 있다면 반환하고 없다면 새 인스턴스를 만들고 캐시한다.
private val cacheData = mutableMapOf<KClass<*>, ClassInfo<*>>()
@Suppress("UNCHECKED_CAST")
operator fun <T : Any> get(cls: KClass<T>): ClassInfo<T> =
cacheData.getOrPut(cls) { ClassInfo(cls) } as ClassInfo<T>
}
ClassInfo는 프로퍼티 이름으로 생성자 파라미터를 제공할 수 있으며, 생성자를 호출하는 코드는 그 파라미터를 파라미터와 생성자 인자를 연결하는 맵의 키로 사용한다.
class ClassInfo<T: Any>(cls: KClass<T>) {
private val constructor = cls.primaryConstructor!!
private val jsonNameToParam = hashMapOf<String, KParameter>()
private val paramToSerializer =
hashMapOf<KParameter, ValueSerializer<out Any?>>()
private val jsonNameToDeserializeClass =
hashMapOf<String, Class<out Any>?>()
init {
constructor.parameters.forEach { cacheDataForParameter(cls, it) }
}
fun getConstructorParameter(propertyName: String) : KParameter =
jsonNameToParam[propertyName]!!
fun deserializeConstructorArgument(
param: KParameter, value: Any?):Any? {
val serializer = paramToSerializer[param]
if(serializer != null) return serializer.fromJsonValue(value)
validateArgumentType(param,value)
return value
}
fun createInstance(arguments: Map<KParameter, Any?>: T {
ensureAllParametersPresent(arguments)
return constructor.callBy(arguments)
}
// ...
}
- 리플렉션 캐시를 사용하면 역직렬화 과정에서 애노테이션을 찾는 과정을 프로퍼티 이름 별로 1번만 수행할 수 있다.
private fun ensureAllParametersPresent(arguments: Map<KParameter, Any?>) {
for(param in constructor.parameters) {
// 디폴트 값이 있다면, param.isOptional이 true 다.
// 파라미터가 널이 될 수 있는 값이라면 디폴트 파라미터로 null 을 사용한다.
if(arguments[param] == null &&
!param.isOptional && !param.type.isMarkedNullable) {
throw JKidException("Missing value for parameter ${param.name}")
}
}
}